It’s My Blog It’s My Rules
Since I know this’ll come out Friday, I get to have fun.
I have a feeling most of you know what Candy Crush is. It’s a mindless, infinite thumb scroll replacement.
When you’re playing, Candy Crush will suggest moves to you. It thinks they’re good ideas. Though I don’t know what the algorithm is, it seems to recommend some goofy stuff.
Take this example. It wants me to move the orange piece. It’s not a bad move, but it’s not the best possible move.
Savvy Candy Crush players will see the obvious choice. Make five in a row with the purple pieces, get the cookie thing, cookie thing drops down next to the explodey thing, and when you combine it with the wrapped candy thing, all the purple pieces turn into explodey pieces.
Level over, basically.
But Candy Crush isn’t thinking that far ahead. Neither are missing index requests.

SQL Server Does The Same Thing
Let’s take this query, for example. It’s very Post-centric.
SELECT p.OwnerUserId, p.Score, p.Title
FROM dbo.Comments AS c
JOIN dbo.Posts AS p
ON p.OwnerUserId = c.UserId
WHERE p.PostTypeId = 1
AND p.ClosedDate >= '2018-06-01'
ORDER BY p.Score DESC;
Right now, the only indexes I have are clustered, and they’re not on any columns that help this query. Sure, they help other things, and having clustered indexes is usually a good idea.
This is the home run use-case for nonclustered indexes. You know. Organized copies of other parts of your data that users might query.
This is such an obvious move that SQL Server is all like “hey, got a minute?”
This is where things get all jumpy-blinky. Just like in Candy Crush.
Hints-a-Hints
This is the index SQL Server wants:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts] ([PostTypeId],[ClosedDate]) INCLUDE ([OwnerUserId],[Score],[Title])
Would this be better than no index? Yes.
Is it the best possible index? No. Not by a long shot.
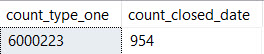
Let’s start with our predicates. SQL Server picked PostTypeId as the leading key column.
SELECT SUM(CASE p.PostTypeId WHEN 1 THEN 1 ELSE 0 END) AS [count_type_one],
SUM(CASE WHEN p.ClosedDate >= '2018-06-01' THEN 1 ELSE 0 END) AS count_closed_date
FROM dbo.Posts AS p
Is it selective?
Regardless of selectivity, the missing index request mechanism will always put equality predicates first.
What I’m getting at is that the missing index request isn’t as well thought out as a lot of people hope. It’s just one possible index for a query weighted to helping us find data in the where clause.
With a human set of eyes on it, you may discover one or more better possible indexes. You may even discover one on for the Comments table, too.
Other Issues
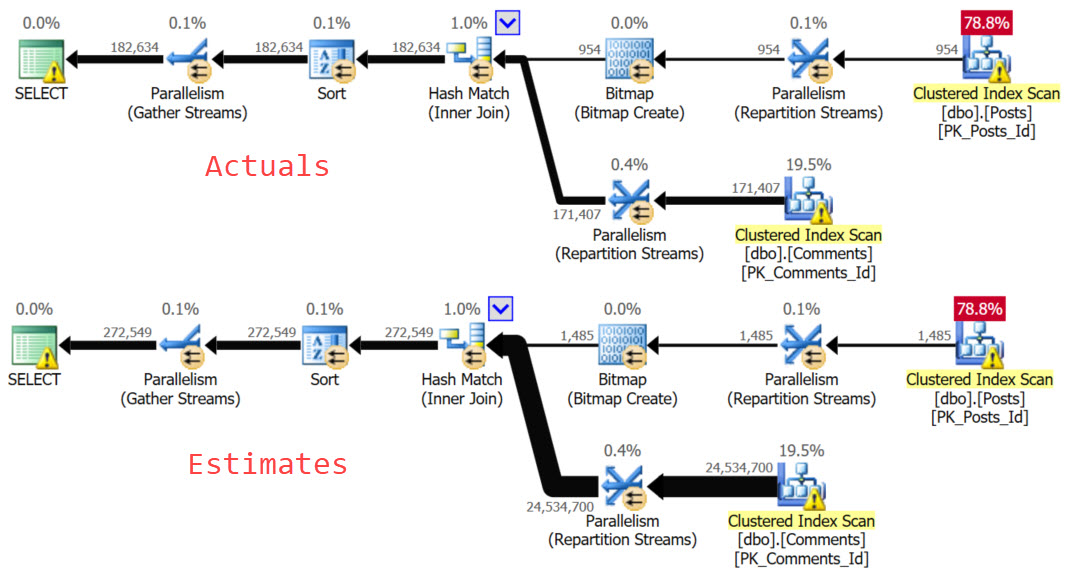
There’s also the issue of the included columns it chose. We’re ordering by Score. We’re joining on OwnerUserId.
Those may be helpful as key columns, depending on how much data we end up joining, and how much data we end up sorting.
Complicated Game
If you don’t have anyone doing regular index tuning, missing index hints are worth following because they’re better than nothing.
They’re like… acceptable. Most of the time.
The big things you have to watch out for are the incredibly wide requests, duplicative requests, and ones that want big string columns.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.