Sorta Topical
Like most tricks, this has a specific use case, but can be quite effective when you spot it.
I’m going to assume you have a vague understanding of parameter sniffing with stored procedures going into this. If you don’t, the post may not make a lot of sense.
Or, heck, maybe it’ll give you a vague understanding of parameter sniffing in stored procedures.
One For The Money
Say I have a stored procedure that accepts a parameter called @Reputation.
The body of the procedure looks like this:
SELECT TOP (1000)
u.*
FROM dbo.Users AS u
WHERE u.Reputation = @Reputation
ORDER BY u.CreationDate DESC;
In the users table, there are a lot of people with a Reputation of 1.
There are not so many with a Reputation of 2.
+------------+---------+ | Reputation | records | +------------+---------+ | 1 | 1090043 | | 2 | 1854 | +------------+---------+
Two For The Slow
Data distributions like this matter. They change how SQL Server approaches coming up with an execution plan for a query.
Which indexes to use, what kind of joins to use, how to aggregate data, if the plan should be serial or parallel…
The list goes on and on.
In this case, we have a narrow-ish nonclustered index:
CREATE INDEX whatever
ON dbo.Users (Reputation, Age, CreationDate);
When I run my stored procedure and look for Reputation = 2, the plan is very fast.
EXEC dbo.WORLDSTAR @Reputation = 2;
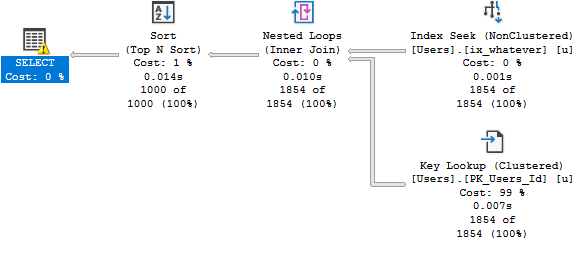
This is a great plan for a small number of rows.
When I run it for a large number of rows, it’s not nearly as fast.
EXEC dbo.WORLDSTAR @Reputation = 1;
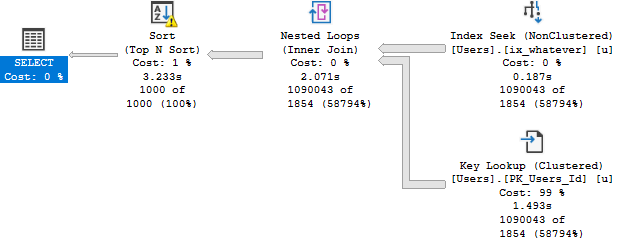
We go from a fraction of a second to over three seconds.
This is bad parameter sniffing.
If we run it for Reputation = 1 first, we don’t have the same problem.
That’s good(ish) parameter sniffing.
Better For Everyone
Many things that prevent parameter sniffing will only give you a so-so plan. It may be better than the alternative, but it’s certainly not a “fix”.
It’s possible to get a better plan for everyone in this situation by re-writing the Key Lookup as a self join
SELECT TOP (1000)
u2.*
FROM dbo.Users AS u
JOIN dbo.Users AS u2
ON u.Id = u2.Id
WHERE u.Reputation = @Reputation
ORDER BY u.CreationDate DESC;
The reason why is slightly complicated, but I’ll do my best to explain it simply.
Here’s what the bad parameter sniffing plan looks like for each query.
Note that the Key Lookup plan still runs for ~3 seconds, while the self-join plan runs for around half a second.
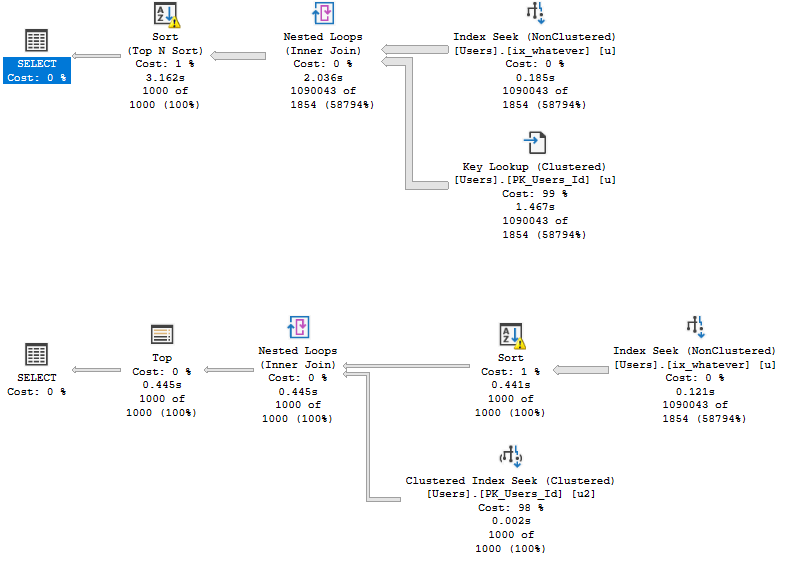
While it’s possible for Key Lookups to have Sorts introduced to optimize I/O… That doesn’t happen here.
The main difference between the two plans (aside from run time), is the position of the Sort.
In the Key Lookup plan (top), the Key Lookup between the nonclustered and clustered indexes runs to completion.
In other words, for everyone with a Reputation of 1, we go to the clustered index to retrieve the columns that aren’t part of the nonclustered index.
In the self-join plan (bottom), all rows go into the Sort, but only the 1000 come out.
Different World
The difference is more obvious when viewed with Plan Explorer.
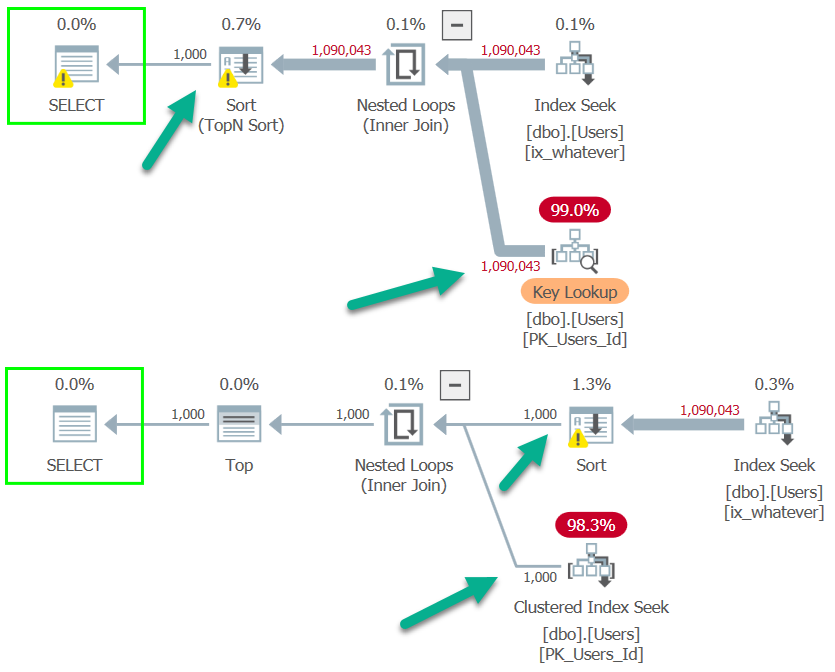
In the Key Lookup plan, rows aren’t narrowed until the end so a seek occurs ~1mm times.
In the self-join plan, they’re eliminated directly after the Index Seek, so the join only runs for 1000 rows and produces 1000 seeks.
This doesn’t mean that Top N Sorts are bad, it just means that they may not produce the most optimal plans for Key Lookups.
When This Doesn’t Work
Without a TOP, the self-join pattern isn’t as dramatically faster, but it is about half a second better (4.3s vs. 3.8s) for the bad parameter sniffing scenario, and far less for the others.
Of course, an index change to put CreationDate as the second key column fixes the issue by removing the need to sort data at all.
CREATE INDEX whatever --Current Index
ON dbo.Users (Reputation, Age, CreationDate);
GO
CREATE INDEX apathy --Better Index For This Query
ON dbo.Users (Reputation, CreationDate, Age);
GO
But, you know, not everyone is able to make index changes easily, and changing the key column order can cause problems for other queries.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- SQL Server 2022 CTP 2.1 Improvements To Parameter Sensitive Plan Optimization
- SQL Server 2022 Parameter Sensitive Plan Optimization: Does Not Care To Fix Your Local Variable Problems
- SQL Server 2022 Parameter Sensitive Plan Optimization: How PSP Can Help Some Queries With IF Branches
- SQL Server 2022 Parameter Sensitive Plan Optimization: Sometimes There’s Nothing To Fix
SQL would be smarter if it used different plans for different parameters.
Why don’t we help it out a bit?
if( @reputation == 1 )
SELECT TOP (1000) u.* FROM dbo.Users AS u WHERE u.Reputation = 1 ORDER BY u.CreationDate DESC;
else
SELECT TOP (1000) u.* FROM dbo.Users AS u WHERE u.Reputation = @Reputation ORDER BY u.CreationDate DESC;
Could one use a CTE to produce a similar result (early sort in the execution plan)?
Alternatively, are there any downsides to slapping an OPTION (RECOMPILE) on a query that has a funky distribution? The main downsides I’m aware of are: 1. expensive if the query is run a lot and 2. you miss out on some helpful stats that could be gleaned from the DMV’s.
RE: a CTE — yeah, maybe sorta kinda. You’d have to play some tricks, most likely.
Yeah, those are about the downsides of recompile. You can offset the DMV issue with a good monitoring tool, though.
That was a super interesting stackexchange post – thanks for the link!