Let’s Run A Cruddy Query
We’ve got no supporting indexes right now. That’s fine.
The optimizer is used to not having helpful indexes. It can figure things out.
SELECT p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
ORDER BY p.Id;
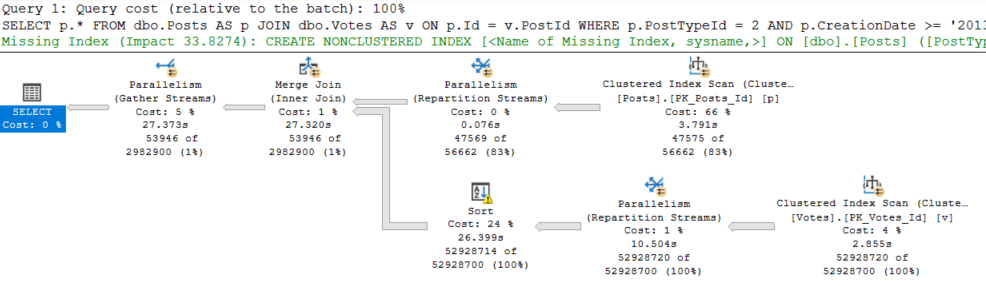
So uh. We got a merge join here. For some reason. And a query that runs for 27 seconds.
The optimizer was all “no, don’t worry, we’re good to sort 52 million rows. We got this.”
[You don’t got this — ED]
Choices, Choices
Since we have an order by on the Id column of the Posts table, and that column is the Primary Key and Clustered index, it’s already in order.
The optimizer chose to order the PostId column from the Votes table, and preserve the index order of the Id column.
Merge Joins expect ordered input on both sides, don’tcha know?
It could have chosen a Hash Join, but then the order of the Id column from the Posts table wouldn’t have been preserved on the other side.
Merge Joins are order preserving, Hash Joins aren’t. If we use a Hash Join, we’re looking at ordering the results of the join after it’s done.
But why?
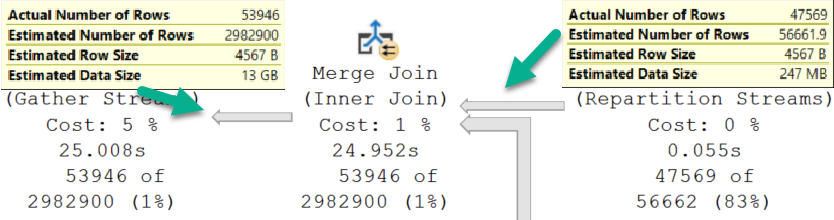
Going into the Merge Join, we have a Good Guess™
Coming out of the Merge Join, we have a Bad Guess™
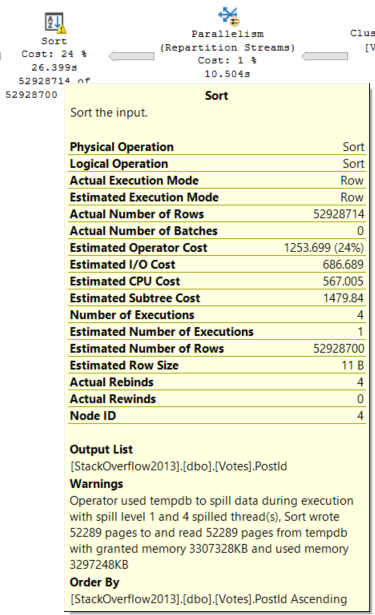
Thinking back to the Sort operator, it only has to order the PostId column from the Votes table.
That matters.
Hash It Up
To compare, we need to see what happens with a Hash Join.
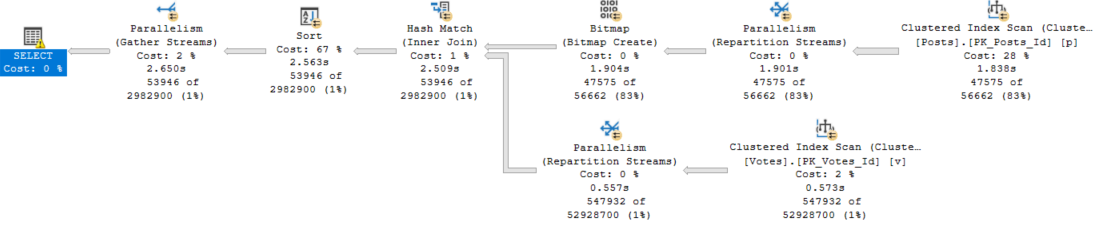
Okay, ignore the fact that this one runs for 2.6 seconds, and the other one ran for 27 seconds.
Just, like, put that aside.
Here’s why:
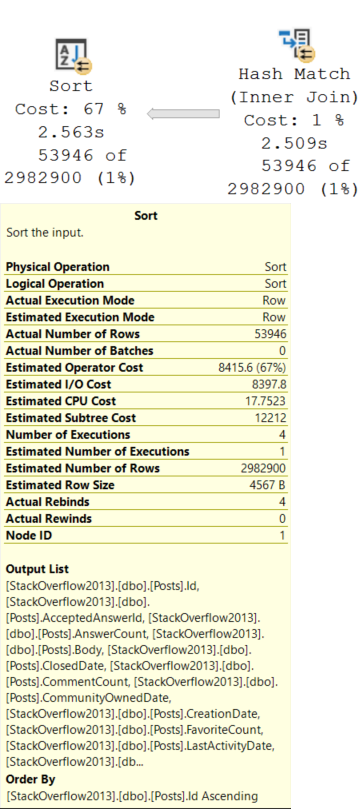
This Sort operator is different. We need to sort all of the columns in the Posts table by the Id column.
Remember that the Id column is now out of order after the Hash Join.
Needing to sort all those columns, including a bunch of string columns, along with an NVARCHAR(MAX) column — Body — inflates the ever-weeping-Jesus out of the memory grant.
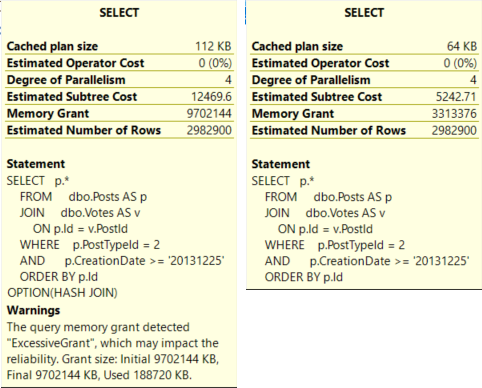
The Hash Join plan is not only judged to be more than twice as expensive, but it also asks for a memory grant that’s ~3x the size of the Merge Join plan.
Finish Strong
Let’s tally up where we’re at.
Both queries have identical estimated rows.
The optimizer chooses the Merge Join plan because it’s cheaper.
- The Merge Join plan runs for 27 seconds, asks for 3.3GB of RAM, and spills to disk.
- The Hash Join plan runs for 3 seconds, asks for 9.7GB of RAM and doesn’t spill, but it only uses 188MB of the memory grant.
That has impacted the reliability.
In a world where memory grants adjust between executions, I’ll take the Hash Join plan any day of the week.
But this is SQL Server 2017, and we don’t get that without Batch Mode, and we don’t get Batch Mode without playing some tricks.
There are lots of solutions if you’re allowed to tune queries or indexes, but not so much otherwise.
In the next couple posts, I’ll look at different ways to approach this.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Hey Erik, how did you force the hash join in query 2? Just with a hint, or did you change the query?
Yep, just an OPTION(HASH JOIN) hint.