Rop-A-Dop
After a while tuning a query, sometimes it’s fun to mess with the DOP it’s run at to see how things change.
I wouldn’t consider this a query tuning technique, more like a point of interest.
For a long time, when I’d look at a serial plan, and then a parallel plan for a query, the shape would be the same.
But that’s not always true.
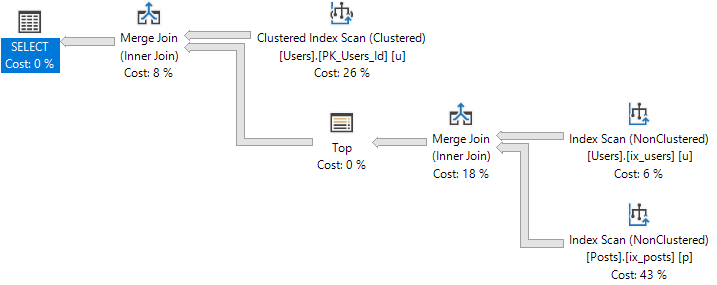
DOP 1
At DOP 1, the plan looks like this:
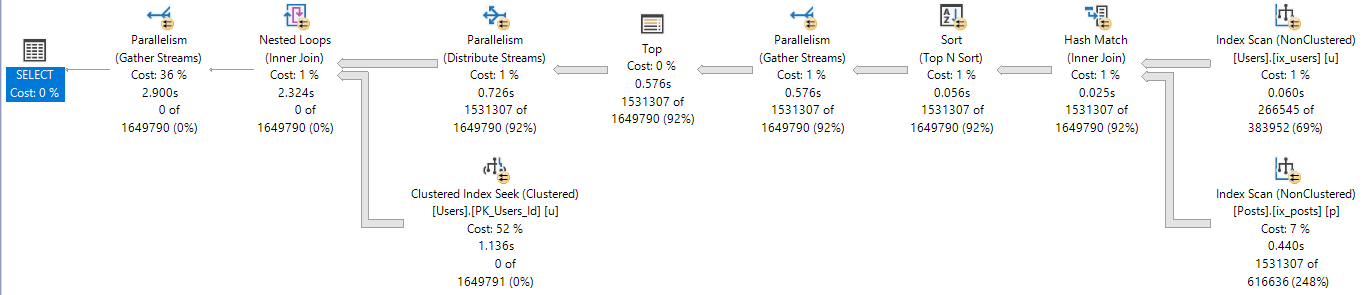
DOP 2
At DOP 2, the plan looks like this:
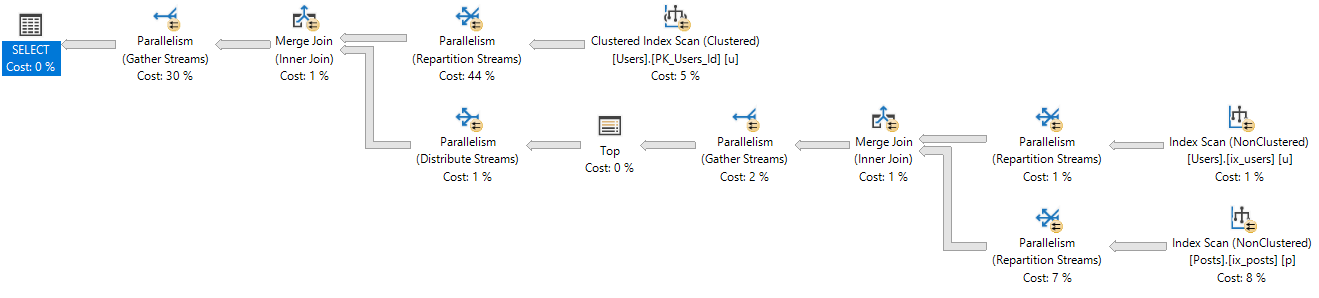
Mo’ DOP
At DOP 3-8, the plan looks like this:
No DOP
The DOP 2 plan has a significantly different shape than the serial, or more parallel plans.
It also chooses different types of joins.
Of course, we can use a merge join hint to have it pick the same plan as higher DOPs, but where’s the fun in that?
Anyway, the reason I found this interesting is because I always thought the general optimization process was:
- Come up with a serial plan
- If the plan cost is > CTFP, look at the parallel version of the serial plan
- If the parallel version is cheaper, go with it
Though it appears like there’s an extra step where the optimizer considers multiple parallel alternatives to the serial plan, and not just the parallel version of the serial plan.
The process is closer to:
- Come up with a serial plan
- If the plan cost is > CTFP, create a *NEW* plan using parallelism
- If the parallel version is cheaper, go with it
In many cases, the *NEW* plan will be the “same” as the serial plan, just using parallelism. The optimizer is a creature of habit, and applies the same rules and transformations.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Hi Erik, i follow your blog post regularly as they indeed help me in day to day query tuning. I have a request. Can you blog something for large tables with partitioning enabled. I really get confused with all that partition elimination stuff which makes me hard to understand when will queries go fast or slow
I don’t really blog much about partitioning because it’s not really a performance feature. It’s for data management. Partition elimination is nice when it happens, but it’s about the same as a good index seek. That changes with clustered column store, but there are people out there who are much better with that than I am.
Thanks!
Thanks Eric, nice summary. Just for the sake of it, I’d be interested in which of those plans executed faster, or had less logical reads! In my time with SQL I’ve absolutely seen different plans and thus performance with different MAXDOP levels, and on rare occasions times we’ve decided to force MAXDAOP=1 for some queries to get predictable outcome on performance (mostly for larger tables, or those with significant change). All up the SQL optimiser is absolutely a work of art!
That’s tricky to answer, because the plan at DOP 3+ is the one from my Exchange Spills post, that runs for quite a long time. Heh.