I am a heading
In the age of column store indexes, indexed views have a bit less attractiveness about them. Unless of course you’re on Standard Edition, which is useless when it comes to column store.
I think the biggest mark in favor of indexed views over column store in Standard Edition is that there is no DOP restriction on them, where batch mode execution is limited to DOP 2.
https://erikdarling.com/sql-server/how-useful-is-column-store-in-standard-edition/
One of the more lovely coincidences that has happened of late was me typing “SQL Server Stranded Edition” originally up above.
Indeed.
There are some good use cases for indexed views where column store isn’t a possibility, though. What I mean by that is they’re good at whipping up big aggregations pretty quickly.
Here are some things you oughtta know about them before trying to use them, though. The first point is gonna sound really familiar.
First, there are some session-level settings that need to be appropriately applied for them to be considered by the optimizer. This is especially important if you’re putting any logic into a SQL Server Agent job, because it uses the wrong settings for some reason.
Here are the correct settings:
- QUOTED_IDENTIFIER ON
- ANSI_NULLS ON
- ANSI_PADDING ON
- ANSI_WARNINGS ON
- ARITHABORT ON
- CONCAT_NULL_YIELDS_NULL ON
- NUMERIC_ROUNDABORT OFF
Second, you’ll wanna use the NOEXPAND hint when you touch an indexed view. Not only because that’s the only way to guarantee the view definition doesn’t get expanded by the optimizer, but also because (even in Enterprise Edition) that’s the only way to get statistics generated on columns in the view.
If you’ve ever seen a warning for missing column statistics on an indexed view, this is likely why. Crazy town, huh?
Third, indexed views maintain changes behind the scenes automatically, and that maintenance can really slow down modifications if you don’t have indexes that support the indexed view definition.
https://erikdarling.com/sql-server/indexed-view-maintenance-is-only-as-bad-as-your-indexes/
Fourth, you have to be REALLY careful if your indexed view is going to span more than one table.
Locking can get really weird, and as tables get super big maintenance can turn into a nightmare even with good indexes to back the join up.
Fifth, there are a ridiculous number of restrictions. The current docs look like this:
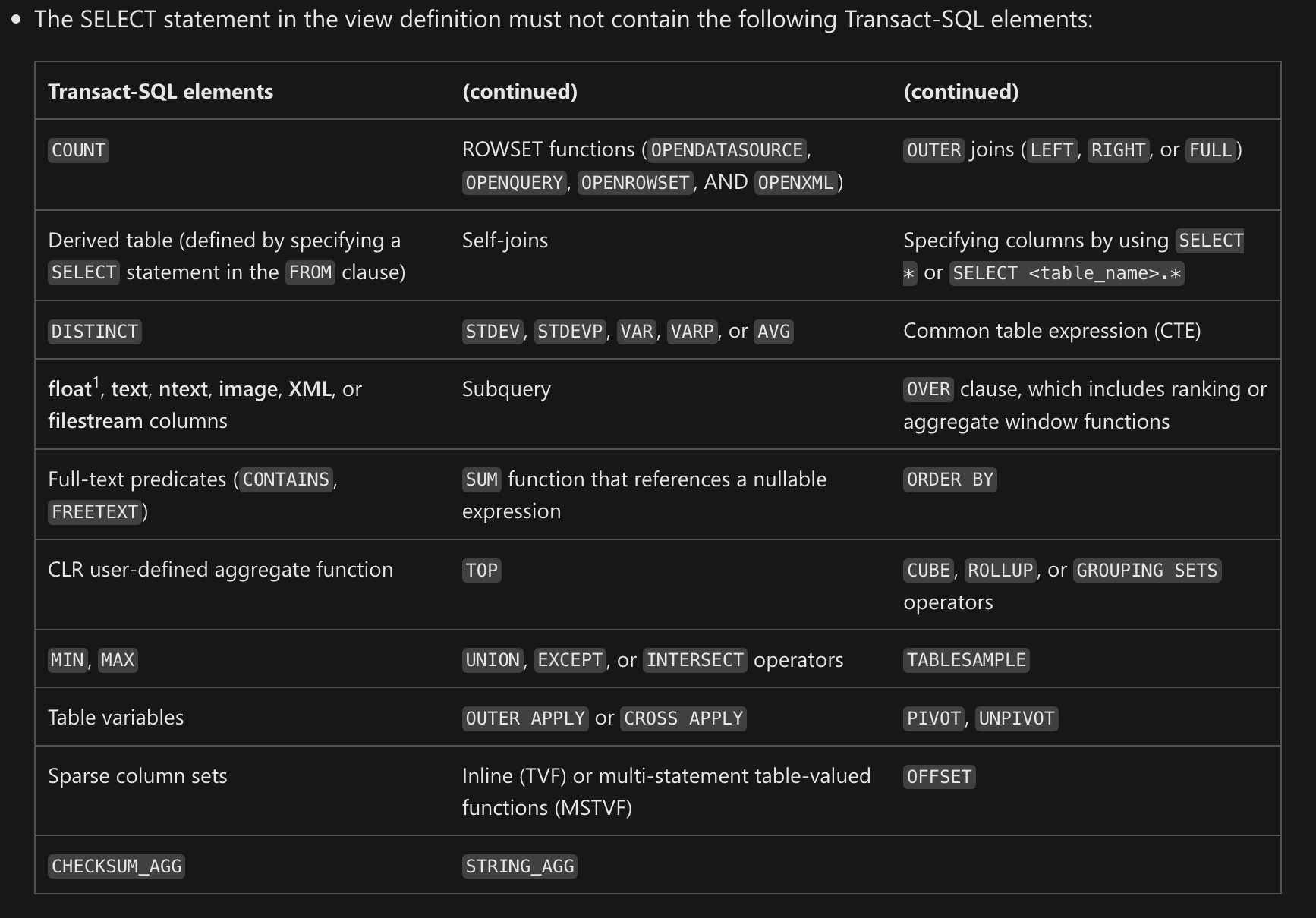
Sixth, you need to be really careful when you alter and indexed view.
When you do that, all of the indexes and statistics get dropped.
Seventh, indexed views can be used a lot like other constructs we’ve talked about this week:
Eighth, if your indexed view has an aggregation in it, you need to have a COUNT_BIG(*) column in the view definition.
Buuuuuut, if you don’t group by anything, you don’t need one.
Ninth, yeah, you can’t use DISTINCT in the indexed view, but if you can use GROUP BY, and the optimizer can match queries that use DISTINCT to your indexed view.
CREATE OR ALTER VIEW
dbo.shabu_shabu
WITH SCHEMABINDING
AS
SELECT
u.Id,
u.DisplayName,
u.Reputation,
Dracula =
COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation > 100000
GROUP BY
u.Id,
u.Reputation,
u.DisplayName;
GO
CREATE UNIQUE CLUSTERED INDEX
cuqadoodledoo
ON dbo.shabu_shabu
(
Id
);
SELECT DISTINCT
u.Id
FROM dbo.Users AS u
WHERE u.Reputation > 100000;
Ends up with this query plan:

Tenth, the somewhat newly introduced GREATEST and LEAST functions do work in indexed views, which certainly makes things interesting.
I suppose that makes sense, since they’re probably just CASE expressions internally, but after everything we’ve talked about, sometimes it’s surprising when anything works.
Despite It All
When indexed views are the right choice, they can really speed up a lot of annoying aggregations among their other utilities.
This week we talked a lot about different things we can do to tables to make queries faster. This is stuff that I end up recommended pretty often, but there’s even more stuff that just didn’t make the top 5 cut.
Next week we’ll talk about some database and server level settings that can help fix problems that I end up telling clients to flip the switch on.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I like the idea of indexed views. In practice, I’ve had a difficult time adding them to large tables as the act of creating the clustered index is, as a former coworker put it in another context, “incompatible with life”. Which is to say that _something_ in the production workload inevitably gets blocked and then I’ve got some ‘splainin’ to do. So until that create index statement supports “with online = on” or unless I predict Future Crimes™ and have foresight to create the indexed view ahead of time, this isn’t a tool in my box.
Maybe you just need MOREDOP
create the indexed view on copies then replace the original tables with synonyms
Can you elaborate, Gordy? For this to work, I’d need to keep the copied tables up to date with changes to the base table(s) while the indexed view is being created. How does that happen? Also, the last time I tried this, the table was several hundred gigabytes (if not into the single-digit terabyte) range with hundreds of billions of rows. So I’d need space enough to have a full copy of the data. These are all surmountable problems, but they’re a lot of hoops to jump through for something that should work on its own.
typically the delta from after the index is created is small enough to sync up before swapping in the synonyms but in extreme cases you can temporarily wireup triggers to capture what’s changed (in yet another table) while the work happens – it’s a bit of a hassle to be sure but indexed views are usually worth it especially if your tables are huge