I recently ran into a production issue where a SELECT query that referenced a NOLOCK-hinted table was hitting a 30 second query timeout. Query store wait stats suggested that the issue was blocking on a table with a nonclustered columnstore index (NCCI). This was quite unexpected to me and I was eventually able to produce a reproduction of the issue. I believe this to be a bug in SQL Server that’s present in both RTM and the current CU as of this blog post (CU14). The issue also impacts CCIs as well but I did significantly less testing with that index type.
The Setup
First I’ll create a heap with 500k rows. All of the rows have the same value. I’ll also create an NCCI on the single column of the table.
DROP TABLE IF EXISTS dbo.TEST_NCCI_1; CREATE TABLE dbo.TEST_NCCI_1 ( ID VARCHAR(10) NOT NULL ); INSERT INTO dbo.TEST_NCCI_1 SELECT TOP (500000) '1' FROM master..spt_values t1 CROSS JOIN master..spt_values t2; CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI ON dbo.TEST_NCCI_1 (ID) WITH (MAXDOP = 1);
The NCCI has a single compressed rowgroup with no rows in the delta store or delete buffer. It’s an honest table and I’m not trying to trick you:
![]()
We also need a table to join to. A heap with a single row will serve that need:
DROP TABLE IF EXISTS dbo.JOIN_TO_ME;
CREATE TABLE dbo.JOIN_TO_ME (
ID VARCHAR(10) NOT NULL
);
INSERT INTO dbo.JOIN_TO_ME VALUES ('1');
Suppose a different session has a long held exclusive table lock on TEST_NCCI_1. For example, the code below could be running in a different session with a yet to be committed transaction:
BEGIN TRANSACTION; SELECT TOP (1) * FROM dbo.TEST_NCCI_1 WITH (TABLOCKX);
Would you expect the following query to be blocked by the open transaction?
SELECT COUNT_BIG(*) FROM dbo.TEST_NCCI_1 a WITH (NOLOCK) Left Outer Join dbo.JOIN_TO_ME b WITH (NOLOCK) ON a.ID = b.ID;
Test Results
I ran 45 tests in total by varying the isolation level (SET TRANSACTION ISOLATION LEVEL) and the locking hint at the table level. You may be wondering why I bothered to do so. According to the documentation, a table level locking hint overrides the isolation level for read operations:
Only one of the isolation level options can be set at a time, and it remains set for that connection until it is explicitly changed. All read operations performed within the transaction operate under the rules for the specified isolation level unless a table hint in the FROM clause of a statement specifies different locking or versioning behavior for a table.
This is not what I observed which is part of why I believe that the current behavior in SQL Server should be considered a bug. In the table below, “YES” means that the query was blocked and “NO” means the query was able to execute. I used red font for the behavior which I believe to be in error based on my understanding of expected locking behavior in SQL Server.
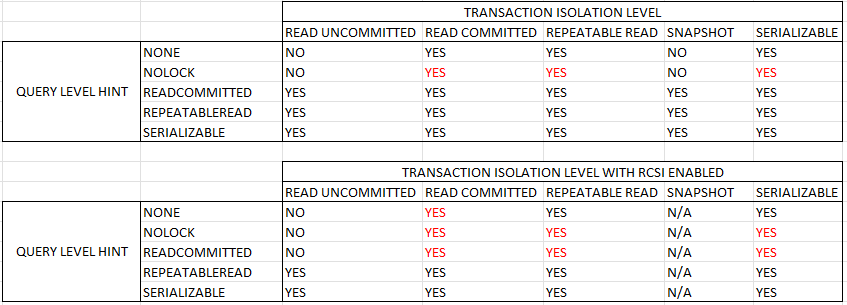
To summarize the results:
- The query is always blocked under the read committed, repeatable read, and serializable isolation levels. The table locking hint does not matter.
- Blocking behavior works as expected under the read uncommitted and snapshot isolation levels.
- RCSI does not help here. With RCSI, to avoid getting blocked you need to set the transaction isolation level to READ UNCOMMITTED.
I was able to use the lock_acquired extended event to see the problematic requested lock. In the screenshot below, the results are filtered to the object level. The first set of locks that occurred around the 11 second mark were under the read uncommitted isolation level. The second set of locks at around the 21 second mark where under the read committed isolation level. A table level NOLOCK hint was included for both queries.
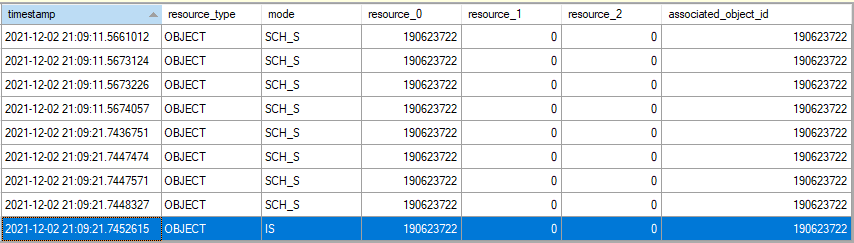
To be clear, it is unexpected to see an IS object lock for a SELECT query with a table level NOLOCK hint. As far as I can tell, there are no interesting locks taken after the IS lock is acquired:

I attempted to investigate further by getting callstacks before the IS lock is acquired:
sqlmin.dll!XeSqlPkg::lock_acquired::Publish+0x228
sqlmin.dll!lck_lockInternal+0x1139
sqlmin.dll!LockAndCheckState+0x2c5
sqlmin.dll!GetHoBtLockInternal+0x445
sqlmin.dll!ColumnDataSetSession::WakeUp+0xa86
sqlmin.dll!NormalColumnDataSet::WakeUp+0xe
sqlmin.dll!ColumnDataSetSession::Create+0x183
sqlmin.dll!ColumnsetSS::WakeUpInternal+0x1ec
sqlmin.dll!ColumnsetSS::WakeUp+0x15e
sqlmin.dll!CreateDictionaryRowsetHelper+0x250
sqlmin.dll!CBpLocalDictionaryManager::GetSEStringDictionaryRowset+0x416
sqlmin.dll!CBpLocalDictionaryManager::FGetData+0xd1
sqlmin.dll!CBpDeepDataContextForBatch::GetStringValue+0x1d
sqlTsEs.dll!CTEsHashMultiData<167,1>::MdEsIntrinFn<CMDPureInput,CMDIteratorAllPureInputs>+0x13d
sqlTsEs.dll!CEsMDIntrinsicWrapper::UnaryImpl<&CTEsHashMultiData<167,1>::MdEsIntrinFn<CMDPureInput,CMDIteratorAllPureInputs>,&CTEsHashMultiData<167,1>::MdEsIntrinFn<CMDImpureInput,CMDIterator> >+0xd1
sqlTsEs.dll!CEsExecMultiData::GeneralEval+0x188
sqlTsEs.dll!CMultiDataEsRuntime::Eval+0x247
sqlmin.dll!CBpComputeMulticolumnHashRunTime::Eval+0x5b7
sqlmin.dll!CBpPartialJoin::ProcessProbeSide+0x445
sqlmin.dll!CBpQScanHashJoin::Main+0x148
sqlmin.dll!CBpQScanHashJoin::BpGetNextBatch+0x28
sqlmin.dll!CBpQScan::GetNextBatch+0x6f
sqlmin.dll!CBpChildIteratorScanner::BpGetNextBatch+0x12
sqlmin.dll!CBpQScanHashAggNew::ProcessInput+0x8b
I’m not terribly surprised to see a reference to a dictionary in the callstacks because I’m not able to reproduce the issue with an INT or BIGINT column. However, I have no idea where to go from here.
Workarounds
Adding an IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX query hint was an effective workaround for all of my test cases. I experienced the expected locking behavior for all test cases with that hint, so it is apparent to me that the issue is caused by the query plan reading from the NCCI.
Disabling batch mode using the DISALLOW_BATCH_MODE use hint seems to be an effective workaround as well, but I did not test this as thoroughly.
Changing the isolation level may also be an acceptable way to avoid the unexpected blocking for some scenarios. For example, if you already have a NOLOCK table hint in place then changing the transaction isolation level to read uncommitted may not introduce any new data correctness issues.
Final Thoughts
For some queries, a simple join on a VARCHAR column between a table with a columnstore index and another table can lead to unexpected blocking, even with a table level NOLOCK hint or with read committed snapshot isolation enabled for the database. This is frustrating and disappointing behavior from a concurrency perspective. It is an odd scenario where enabling snapshot isolation offers a significant benefit over enabling read committed snapshot isolation. I hope that this locking behavior changes in a future version of SQL Server. Thanks for reading!
Hi Joe, I ran into something similar with an Indexed view.
https://straightforwardsql.com/posts/is-lock-in-rcsi-enabled-database/
Hi Joe, thank you for this article.
I ran into a somewhat similar issue in our production database (SQL2016 SP2 CU15).
We have a set of reporting stored procs that read (under read-committed) from a few big fact tables, which, in their turn, are updated on a regular basis (every few minutes) by a background ServiceBroker-initiated workflow (which operates under serializable isolation level).
For obvious reasons, I am using RCSI in this database – to make sure these stored procs do not get blocked by this background workflow.
However, I noticed that when I create a NCCI-index on some of these big tables, these stored procs sometimes do get blocked – regardless of the RCSI enabled.
In my opinion, it contradicts the official documentation that states that “Columnstore indexes support read committed snapshot isolation level (RCSI) and snapshot isolation (SI).”
(https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-what-s-new?view=sql-server-ver15)
I might be missing some known gotchas here, and I have not done a thorough investigation on it yet, but it feels like there are scenarios when RCSI does not get along with NCCI indexes and vice versa.