If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
So I find myself in a difficult position: do I dredge up more red meat for the millions of die-hard SQL Server performance nuts who come here for the strange and outlandish, or produce evergreen content for people who pay my substantial bar tabs.
Coin, tossed.
Corn, popped.
Greenery
Local variables present an attractive proposition for many reasons. For instance, you can:
Set a constant date/time variable
Assign values from complex subqueries to a single variable
Increment values in a loop to batch modifications
And here’s the thing: I’m with you on the need and convenience for all those things. It’s just how you usually end up using them that I disagree with.
Many developers are under the impression that parameter sniffing is a bad thing; it is not. If it were, modern database systems would have thrown the whole idea out ages ago.
Constantly generating execution plans is not a good use of your CPU’s brain power. The real problem is parameter sensitivity.
I’m going to say this as emphatically as I can for those of you who call local variables and using optimize for unknown as a best practice:
Local variables use an estimate derived from the total rows in the table multiplied by the assumed uniqueness of a column’s data. More often than not, that is a very small number.
If you have the kind of incredibly skewed data that is sensitive to parameters being sniffed, and plans being generated based on those initial estimates, it is highly unlikely that plans derived from fuzzy math will be suitable for general execution.
There may be exceptions to this, of course.
Every database is subject to many local factors that make arrangements outside the norm being sensible.
Drudgery
What you need to do as a developer is test these assumptions of yours. I spend a lot of my time fixing performance problems arising developers not testing assumptions.
A common feedback loop occurs when testing code against very small data sets that don’t expose the types of performance problems that arise from larger ones, or testing against data sets that may be similar in terms of volume, but not in terms of distribution.
I am being charitable here, though. Most code is only tested for result correctness. That’s a fine starting point.
After all, most developers are paid to develop, and are not performance tuning experts. It would be nice if performance tuning were part of the development process, but… If you’re testing against wack data, it’s impossible.
Timelines are short, demands are substantial, and expectations are based mostly around time to deliver.
Software development against databases is rarely done by developers who are knowledgable about databases, and more often than not by developers who are fluent in the stack used for the application.
Everything that happens between front and back may as well be taking place in Narnia or Oz or On A Planet Far, Far Away.
This section ended up being way more philosophical than I had intended, but it’s Côte-Rôtie season.
Let’s move on!
Assumptive
When you want to test whether or not something you’re working on performs best, you need to understand which options are available to you.
There are many ways to pet a dog when working with SQL Server. Never assume the way you’re doing it is the best and always the best.
One assumption you should absolutely never make is that the way you see everyone around you doing something is the best way to do something.
That’s how NOLOCK turned into an epidemic. And table variables. And Common Table Expressions. And Scalar UDFs. And Multi-Statement UDFs. And sticking ISNULL in every join and where clause.
And, of course, local variables.
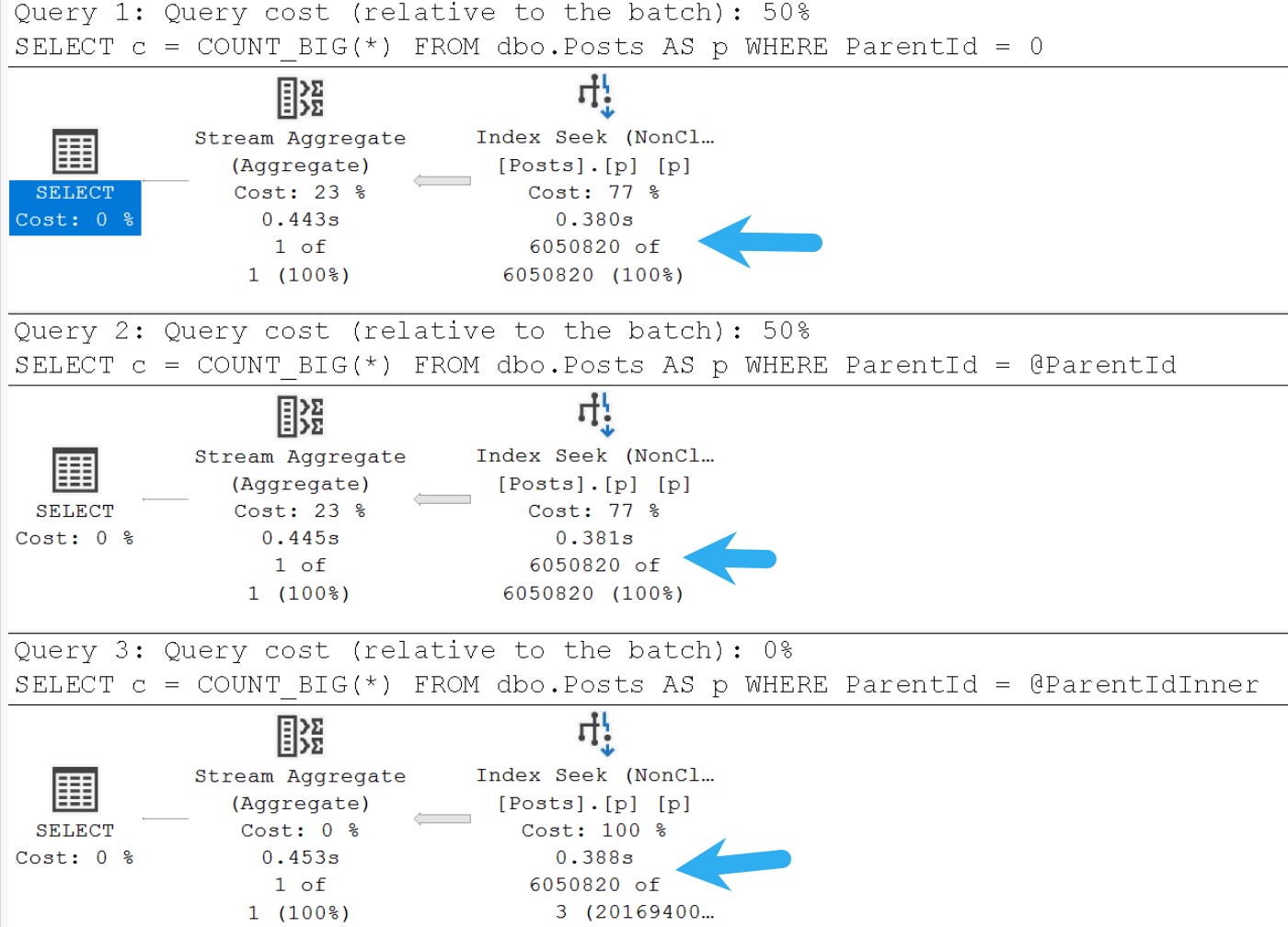
One way to test your assumptions about things is to create a temporary stored procedure and test things in different ways.
CREATE OR ALTER PROCEDURE
#p
(
@ParentId integer
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@ParentIdInner integer = @ParentId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE ParentId = 0;
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE ParentId = @ParentId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE ParentId = @ParentIdInner;
END;
GO
CREATE INDEX
p ON
dbo.Posts
(ParentId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
EXEC dbo.#p
@ParentId = 0;
We’re using:
A literal value
An actual parameter
A declared variable
With an example this simple, the local variable won’t:
Slow things down
Change the query plan
Prevent a seek
But it will throw cardinality estimation in the toilet and flush twice.
grimy
These are the kinds of things you need to test and look at when you’re figuring out the best way to pet SQL Server and call it a very good dog.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
There are two forms of conditional logic that I often have to fix in stored procedures:
Branching to run different queries at different times
Complicated join and where clause logic
The problems with both are similar in terms of performance. You see, when smart people tell you that SQL is a declarative language, and not a procedural language, they’re usually trying to get you to stop using cursors.
And that’s not always wrong or bad advice, trust me. But it also applies here.
When you’re developing stored procedures, the thing you need to understand is that SQL Server builds query plans for everything in them first time on the first compile, and then after any causes of a recompile.
It does not compile for just the branch of logic that gets explored on compilation. No no. That would be too procedural. Procedural we are not.
There are two exceptions to this rule:
When the branches execute dynamic SQL
When the branches execute stored procedures
If this sounds familiar to you, you’ve probably hear me talk about parameter sniffing, local variables, SARGability, and… well, more things dealing with SQL Server performance.
Hm.
Problem 1: IF Branching
Like I mentioned above, the only way to get if branching to only compile plans for explored branches, is to tuck them away.
Probably the easiest way to demonstrate this is to create a stored procedure with logical branching that accesses an object that doesn’t even pretend to exist.
CREATE OR ALTER PROCEDURE
dbo.i_live
(
@decider bit = NULL
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @decider = 'true'
BEGIN
SELECT
dp.*
FROM dbo.DinnerPlans AS dp;
END;
IF @decider = 'false'
BEGIN
SELECT
dp.*
FROM dbo.DinnerPlans AS dp WITH(INDEX = 2);
END;
IF @decider IS NULL
BEGIN
SELECT
result = 'please make a decision.'
END;
END;
GO
EXEC dbo.i_live
@decider = 'true';
If you run this, you’ll get an error saying the index doesn’t exist, even though the code branch doesn’t run.
Where things get even weirder, but is well besides the point of the post, if you execute a store procedure that references a table that doesn’t exist, but not in the branch that executes, no plan will be cached for it.
You may love a big, messy, sloppy, join or where clause, but SQL Server’s query optimizer hates it. This may be disappointing to hear, but query optimization is a really hard job.
Feeding in a bunch of runtime complexity and expecting consistently good results is a shamefully naive approach to query writing.
The query optimizer is quite good at applying its craft to a variety of queries. At the base of things, though, it is a computer program written by people. When you think carefully about the goal of a generalized query optimizer, it has to:
Come up very quickly with a good enough execution plan
Regardless of the surrounding hardware
Respecting the logic of the query
Within the confines of available indexes, constraints, hints, and settings
As you add complexity to queries, various things become far harder to forecast and plan for in a generalized way.
Think of it like planning a car trip. The more stops you add, the harder it is to find the fastest route. Then throw in all the unexpecteds — traffic, construction, weather, people randomly gluing themselves to the road, breakdowns — and what have you got?
Chaos. Pure chaos.
While the idealism of writing everything in one big query seems attractive to SQL developers — stacking common table expressions, nesting view upon view and subquery upon subquery, and adding in all the OR logic one can possible surmise — it only opens the optimizer up to error, mis-estimates, and even missed opportunities.
The reality is that query optimizers across all database platforms have plenty of issues, blind spots, and shortcomings. Sometimes you need to write queries in a way that is less convenient to you in order to avoid them.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
There are only a few data types that make me nervous when I see them:
MAX strings, or approaching the upper byte limit (except for dynamic SQL)
XML
sql_variant
It doesn’t matter if they’re stored procedure parameters, or if they’re declared as local variables. When they show up, I expect something bad to happen.
One thing that makes me really nervous about string data specifically, is that many developers don’t pay close attention to varchar vs. nvarchar.
This doesn’t just apply to stored procedures. Many ORMs suffer the same issue with data types not being strongly typed, so you sometimes end up with all varchar(8000) or nvarchar(4000) input parameters, and other times end up with n/varchar strings with lengths inferred at compile-time based on the length of the string passed in. That means that if you have an ORM query that takes, let’s say a name as input, it might the infer the string as unicode when it shouldn’t, and if you were to pass in different names for different executions, you’d get all different plans, too.
Erik: nvarchar(4)
Kendra: nvarchar(5)
Al: nvarchar(2)
Tom: nvarchar(3)
You get the picture. It’s a nutty nightmare, and it’s made worse if the name column you’re searching is a varchar data type, regardless of length. But those are ORM problems, and we wield mighty stored procedures like sane and rational people.
Let’s play a game called pattern and anti-pattern.
Anti-Pattern: One parameter for searching many columns
The sheer number of times I’ve seen something like this justifies most of the self-medicating I apply to myself.
CREATE OR ALTER PROCEDURE
dbo.BadIdea
(
@SearchString nvarchar(whatever)
)
AS
BEGIN
SET @SearchString = N'%' + @SearchString + N'%';
SELECT
p.*
FROM dbo.Posts AS p
WHERE p.Id LIKE @SearchString
OR p.OwnerUserId LIKE @SearchString
OR p.AcceptedAnswerId LIKE @SearchString
OR p.CreationDate LIKE @SearchString
OR p.LastActivityDate LIKE @SearchString
OR p.Tags LIKE @SearchString
OR p.Title LIKE @SearchString
OR p.Body LIKE @SearchString
ORDER BY
p.ViewCount DESC;
END;
All sorts of bad things happen when you do this. You can’t index for this in any meaningful way, and comparing non-string data types (numbers, dates, etc.) with a double wildcard string means implicit conversion hell.
You don’t want to do this. Ever.
Unless you want to hire me.
Pattern: Properly typed parameters for each column
Rather than get yourself into that mess, create your procedure with a parameter for each column, with the correct data type.
Next, don’t fall into the trap where you do something like (p.OwnerUserId = @OwnerUserId OR @OwnerUserId IS NULL), or anything resembling that.
It’s a rotten idea. Instead, watch this video to learn how to write good dynamic SQL to deal with code like this:
Anti-Pattern: Passing Lists In Parameters And…
Splitting the string directly in your join or where clause.
When you do this, SQL Server can’t make good cardinality estimates, because it has no idea what’s in the list. Worse, I usually see generic string split functions that can deal with any data type as input and output.
You might be outputting wonky data types that compare to column(s) of different data type(s), and suffering implicit conversion woes.
A cleaner option all around is to use Table Valued Parameters, backed by User Defined Table Types with the correct data types.
You may still need to follow my advice below, but it’s a bit easier to manage.
Pattern: Passing Lists In Parameters And…
Dumping the parsed output into a #temp table with the right column data types.
When you do that, two nice things happen:
SQL Server builds a histogram on the values
You can index it for large lists
I find myself changing to this pattern quite a bit when tuning code for clients. They’re often surprised by what a difference it makes.
Even when using Table Valued Parameters, I find myself doing this. Since Table Valued parameters are read only, you don’t need to worry about the contents changing even if you pass them to other procedures.
Anti-Pattern: Using Unnecessary MAX Types
I’ve blogged before about why you shouldn’t declare parameters or variables as MAX types in the past, but the issue is mainly that they can’t be used to seek into an index.
Because of the internals of MAX parameters and variables, you’ll see a filter after data is acquired in the query plan, which is usually much less efficient than filtering out data when a table or index is initially accessed.
It’s also a bad idea for columns in tables for similar reasons. I understand that there is some necessity for them, but you should avoid them for searches as much as possible, and make them retrieve-only in your queries.
A good example is an Entity Attribute Value table, where developers allow searches on the Value column, which is either sql_variant, or nvarchar(max) so that it can accommodate any contents that need to be stored there.
Pattern: Using Reasonable Data Types
The number of times that I’ve seen MAX types used for anything involved in searches that actually needed to be MAX is relatively small compared to the number of times I’ve checked the max length of data and found it to be around 100 bytes or so.
Making significant changes like that to large tables is sometimes painful. Often, it’s easier to add computed columns in various ways to allow searching and indexes to be easier:
TRY_CAST or TRY_CONVERT to integers, dates, etc.
SUBSTRING to an appropriate string type with a reasonable length
Hashing the contents of the column to make binary searches possible
As long as you don’t persist the computed columns, the table isn’t locked when they’re added. However, you do need to index them to make them useful for searching. That will only be painful if you don’t pay Microsoft enough money.
Plans Within Plans
As you review stored procedure code, keep an eye out for these anti-patterns. Fixing small things can have big downstream effects.
While not every change will yield many seconds or minutes of performance improvements, it helps to follow the rules as well as possible to clarify what the real issues are.
Getting a stored procedure to the point where you’re sure exactly what needs to change to improve performance can be a tough task.
Having a mental (or written) checklist of things that you know to fix makes it faster and easier.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I’ve talked about isolation levels a bit lately because I need you all to understand that no isolation level is perfect, and that most everyone is completely wrong about how they really work.
For a very high percentage of workloads, Read Committed Snapshot isolation is the best choice. Why?
Because most developers would expect:
Read queries to not block with write queries
Read queries to not deadlock with write queries
Read queries to return correct results from committed transactions
You only get *one* of those things from Read Committed, but you get all of those things from Read Committed Snapshot Isolation.
Sure, there’s a thing you don’t get from it, but if you want that thing, you have to put up with read queries blocking and deadlocking with write queries.
That thing is: Reading only the most current version of row values, which is the only meaningful guarantee that Read Committed will give you.
If you’ve been battling stupid locking problems for a long time, you’ve probably got NOLOCK hints everywhere, which means you’re not getting that anyway.
You’re getting back garbage.
So hear me out: If you’ve got some queries that require the most current version of row values to work correctly, you have the READCOMMITTEDLOCK table hint to save you.
What Read Committed Doesn’t Get You
To illustrate the concurrency issues that can arise under Read Committed, here are some slides I made for a thing:
read committed: not great
If any of these surprise you, you’re not allowed to argue with me about Read Committed Snapshot Isolation.
Read Committed Snapshot Isolation And Dumb Queries
Queries that are susceptible to race conditions with optimistic isolation levels are queries that are written in stupid ways.
One example is a query like this:
BEGIN TRANSACTION;
DECLARE
@name nvarchar(40) = 'Erik';
UPDATE dp
SET
dp.name = @name,
dp.is_free = 0
OUTPUT
Inserted.*
FROM dbo.DinnerPlans AS dp
WHERE EXISTS
(
SELECT
1/0
FROM dbo.DinnerPlans AS dp2
WHERE dp.id = dp2.id
AND dp2.is_free = 1
);
COMMIT;
It will behave differently under optimistic vs. pessimistic isolation levels. Let’s pretend that two people try to book the very last seat at the very last time.
Under Read Committed, the update to DinnerPlans would block things so that the read in the exists subquery would wait for it to complete, and find no rows.
Under Read Committed Snapshot Isolation, the update to DinnerPlans would generate a row version, and the read in the exists subquery would read that version where it would find a row.
This is, of course, a very stupid query. If you’re just using direct updates, you won’t have problems:
UPDATE
dp
SET
dp.name = N'Erik',
dp.is_free = 0
FROM dbo.DinnerPlans AS dp
WHERE is_free = 1;
For Every Occasion
There are likely times when each and every isolation level is appropriate, or even required, for parts of a workload to function correctly.
Just like settings for parallelism, max server memory, and many other things in SQL Server, it’s your job to set them as appropriate guardrails for the workload as a whole.
Most workloads work better using Read Committed Snapshot Isolation. If there are specific queries in your workload with different needs, you have many wonderful options to fix them.
In some cases the READCOMMITTEDLOCK hint may be the minimum effective dose. You may also read this post and realize that you need a stronger isolation level with better guarantees, like Repeatable Read or Serializable.
Many people are surprised that Repeatable Read only takes its special locks on rows as it’s reading them, and that changes ahead of where the reads have occurred can still occur, and inserts can still occur between rows that have been read.
Like I said before, no isolation level is perfect, and many developers are surprised by the details of each one.
Most people think that Read Committed works the way Serializable does, where the set of rows you’ve read and are yet to read are somehow a golden copy of the data. That is not true.
The misunderstandings usually arise from a lack of testing for expected results under high concurrency.
Tools like SQL Query Stress and ostress can be invaluable for making sure you’re getting what you want from whatever isolation level you’re using.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Locking hints are funny. Normally I see them in awful products like Dynamics, on select queries, and hilarious levels of blocking and deadlocking issues ensue.
Another place where they’re common is when developers think that adding hints like ROWLOCK means you’ll always only ever lock rows, and that you’ll never have lock escalation when you use it.
Both of those things are wrong. Here’s a video about why:
Perhaps I’m a bit salty because I spent a lot of today rewriting merge statements into separate actions. Perhaps I’m just salty generally.
When Do You Need Locking Hints?
Locking hints (aside from NOLOCK), have the most impact when you need to protect data beyond the scope of a single query in a transaction.
They have the second most impact when you’re doing strangeland things in the database, like processing queues. You can see my example of how to do that here: Building Reusable Queues In SQL Server Part 2
More often than not, though, you’ll want to use them if you do things like this:
BEGIN TRANSACTION
DECLARE
@NextUser integer;
SELECT TOP (1)
@NextUser = u.Id
FROM dbo.Users AS u WITH(UPDLOCK, SERIALIZABLE)
WHERE u.LastAccessDate >=
(
SELECT
MAX(u2.LastAccessDate)
FROM dbo.Users AS u2 WITH(UPDLOCK, SERIALIZABLE)
)
ORDER BY
u.LastAccessDate DESC;
INSERT
dbo.Badges
(
Name,
UserId,
Date
)
VALUES
(
N'Most Recent User Award',
@NextUser,
GETDATE()
);
COMMIT;
Why? What if someone else logs in after you assign this variable?
What locking hints do you need each time you touch the Users table?
Do you need a transaction to protect the entire thing?
Look at the join order
What if someone logs in after the first scan of the Users table?
Is this great for concurrency? Well, that depends on how fast the queries are. With some Good Enough™️ indexes, this’ll be just fine.
Without them, you’ll be in a HEAP of trouble. Ahem. This is the time for laughter.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I somehow talked database genius and actual professor Andy Pavlo to talk to me about databases, OtterTune, the future, and who has the best query optimizer.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Automatic tuning is a half-assed feature that has a lot of problems. I wouldn’t trust it any further than I could throw Entity Framework.
Back in October, I opened an issue with Microsoft to document a new-ish stored procedure. It was closed, and to be clear, it was the PM, not the docs team, that refused the request.
Here’s why that’s a bad choice:
This stored procedure exists and can be executed
The only documentation for it is going to be this blog post
Many other configuration procedures that can be misused are documented and regularly executed by end users
For example, sp_configure is well-documented, and there are many changes one could make via those calls to totally hose a SQL Server.
What this would effectively do is turn automatic tuning off for a specific query based on its query_id in Query Store.
If there’s a plan already being forced, you’ll have to unforce the plan too. You can do that with sp_query_store_unforce_plan.
There you have it. Erik Darling cares about you more than Microsoft does.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Transactions and error handling often go hand-in-glove, to make better use of XACT_ABORT, manually manage rollbacks, and try to make the best use of all those ACID properties that database people seem to care deeply about.
The main things to understand about transactions in SQL Server are:
There’s no respect for nested transactions
The default read committed isolation level can be a bad time
Not everything requires an outer transaction
The lack of nested transactions has been well-documented over the years. Though savepoints do exist, they’re not really the same thing.
For the remaining points, let’s talk a little bit more.
Blocking, Blocking, Blocking
This is a big enough problem with singular modification queries under the default Read Committed pessimistic isolation level.
If you’re going to take it upon yourself to involve multiple queries in a transaction, it also falls upon you to make sure that:
You use the appropriate locking hints
You handle any errors and rollbacks
You make sure that thing is as short and sweet as possible
Everything you do between BEGIN TRANSACTION and COMMIT TRANSACTION will hold whatever locks are required or specified until the bitter end.
Think of the duration of a query, and then the duration of a transaction as a whole, as the surface area.
The larger that surface area gets, the more opportunity there is for it to interfere, or be interfered with, by another surface area with a similar trajectory.
You also need to really understand the isolation level in use, and how that can make results weird.
Let’s take this piece of pseudo code, and assume it’s running under the default Read Committed pessimistic isolation level.
BEGIN TRANSACTION
DECLARE
@UserToPromote integer = NULL;
SELECT TOP (1)
@UserToPromote = u.Id
FROM dbo.Users AS u
WHERE u.Reputation = 1
AND EXISTS
(
SELECT
1/0
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.PostTypeId = 1
AND p.Score = 0
)
ORDER BY
u.CreationDate,
u.Id;
/*IRL you might bail here if this is NULL or something*/
WITH
UserToPromote
AS
(
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @UserToPromote
AND p.PostTypeId = 1
AND p.Score = 0
ORDER BY
p.Score,
p.CreationDate
)
UPDATE utp
SET utp.Score += 1
FROM UserToPromote AS utp;
COMMIT TRANSACTION;
Leaving aside some of the obvious stuff that a professional performance tuner would avoid (like local variables), and ignoring the fact that I haven’t done any error handling, what’s wrong with this code?
We only get the first user whose data was currently committed in the Users table
… And who has a question in the Posts table
Then we try to update a row in Posts for that user
What that leaves out is:
The user could delete their profile after we find them
Someone could vote on their question after we find them
They could delete their question after we find them
Read Committed is not a consistent snapshot of your data during a transaction. In a highly transaction environment, all sorts of things can change right underneath you.
All Read Committed guarantees is that the data you read was committed at the time it is read. Quite flimsy once you think about it for a moment.
If you want to avoid those changes, you’d need to add hints like UPDLOCK and SERIALIZABLE to your select query (and exists subquery) to prevent those changes until the update completes.
Even if you were to do all that work in a single query rather than two, you could run into the exact same issues without those locking hints.
Once those read cursors find the row(s) they want, anything goes until the exclusive locks start being taken.
Don’t Transact Me, Bro
Let’s look at some more psuedo code. It’s a pattern I’ve noticed with more than a few clients now.
BEGIN TRY
BEGIN TRANSACTION
INSERT
dbo.HighQuestionScores
(
Id,
DisplayName,
Score
)
SELECT
u.Id,
u.DisplayName,
p.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT
Score =
MAX(p.Score)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.PostTypeId = 1
) AS p
WHERE NOT EXISTS
(
SELECT
1/0
FROM dbo.HighQuestionScores AS hqs
WHERE hqs.Id = u.Id
);
UPDATE hqs
SET hqs.LastQuestionBadge = b.Name
FROM dbo.HighQuestionScores AS hqs
CROSS APPLY
(
SELECT TOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.Id = hqs.Id
AND b.Name LIKE N'%Question%'
ORDER BY
b.Date DESC
) AS b;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK
END;
/*Do some error stuff maybe*/
THROW;
END CATCH;
The idea of the code is to insert any new users to the HighQuestionScores table. For the sake of completeness, let’s say there’s another query in the mix that would update the high score for existing users too.
It’s just invisible 👻
The problem here is also fairly obvious. There’s absolutely no reason to ROLLBACK new users inserted into the table just because the ensuing update query fails for some reason.
Let’s say that the Badges table was recently modified to accommodate a new, longer, badge name, but the HighQuestionScores table wasn’t.
We would get a truncation error, obviously. But that truncation error should not invalidate the new users inserted at all.
Likewise, if our invisible Score update query produced a bigger integer and failed trying to insert it into an integer column, it should not invalidate new users inserted.
It’s not their fault.
The bottom line: Transactions should only encapsulate queries where correctness would be effected by one failing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
The goal of batching modifications is to accomplish large numbers of row modifications with exacerbating locking problems, and being kinder to your server’s transaction log.
There is generally an appreciable difference in transaction time in modifying 1,000 rows and modifying 10,000,000 rows. Go try it, if you don’t believe me.
Probably the canonical post about batching modifications is written by my dear friend Michael J. Swart.
In many cases, that code is good to go right out of the box. Just replace the table and column names.
But you may have other requirements, too.
Control
One post I had an enjoyable time writing was this one, about how to track before and after values when batching updates.
I also talk a little bit at the end about how to retry modifications when they hit deadlocks, but anyway!
This is something most developers don’t think about at the outset of writing batching code: Should I keep all the prior changes if one set of changes produces an error?
Another thing you may need to think about is this: What if data changes in the course of your code?
Lemme give you a couple examples.
Champion
If you do this, which is a subset of my code from the above post:
SELECT
@NextBatchMax =
MAX(x.id)
FROM
(
SELECT TOP (1000)
aia.id
FROM dbo.as_i_am AS aia
WHERE aia.id >= @LargestKeyProcessed
ORDER BY
aia.id ASC
) AS x;
/*Updateroo*/
UPDATE
aia
SET aia.some_date =
DATEADD(YEAR, 1, aia.some_date),
aia.some_string =
aia.some_string + LEFT(aia.some_string, 1)
OUTPUT
Deleted.id, Deleted.some_date, Deleted.some_string
INTO
dbo.as_i_was (id, some_date, some_string)
FROM dbo.as_i_am AS aia
WHERE aia.id >= @LargestKeyProcessed
AND aia.id <= @NextBatchMax;
Or even this:
/*Updateroo*/
UPDATE
aia
SET aia.some_date =
DATEADD(YEAR, 1, aia.some_date),
aia.some_string =
aia.some_string + LEFT(aia.some_string, 1)
OUTPUT
Deleted.id, Deleted.some_date, Deleted.some_string
INTO
dbo.as_i_was (id, some_date, some_string)
FROM dbo.as_i_am AS aia
WHERE aia.id IN
(
SELECT TOP (1000)
aia.id
FROM dbo.as_i_am AS aia
WHERE aia.id >= @LargestKeyProcessed
AND aia.id <= @NextBatchMax
ORDER BY
aia.id ASC
);
There’s a problem, isn’t there?
Isolation Levels
If you’re using:
Read Committed (Pessimistic)
Read Uncommitted (Anarchy)
Only the table that is either only locked when the update runs (first example), or only the instance referenced by the update (second example) will ever have exclusive locks taken against it.
The part of the operation in both examples that only reads from the table will take normal shared locks on rows or pages as the reads happen.
Even under Read Committed (Pessimistic), some lousy things can happen:
You can miss rows that are updated by other processes
You can see rows twice that are updated by other processes
You can include rows that have been deleted by other processes
Read Committed is not a point in time read of all the data your query needs.
Heck, even Repeatable Read (Quite Pessimistic) only locks rows as it needs them. That means rows can change ahead of your seek/scan position freely.
For really interesting cases, you might need to use Serializable (Perfectly Pessimistic) to do your batching.
And Stay Out
I ran into a client process recently that actually had to do this.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION
/*Updateroo*/
UPDATE
aia /* You could also do this WITH (SERIALIZABLE) */
SET aia.some_date =
DATEADD(YEAR, 1, aia.some_date),
aia.some_string =
aia.some_string + LEFT(aia.some_string, 1)
OUTPUT
Deleted.id, Deleted.some_date, Deleted.some_string
INTO
dbo.as_i_was (id, some_date, some_string)
FROM dbo.as_i_am AS aia
WHERE aia.id IN
(
SELECT TOP (1000)
aia.id
FROM dbo.as_i_am AS aia /* You could also do this WITH (SERIALIZABLE) */
WHERE aia.id >= @LargestKeyProcessed
AND aia.id <= @NextBatchMax
ORDER BY
aia.id ASC
);
COMMIT TRANSACTION;
If you’re deleting a small number of rows, and you have appropriate indexes in place to support your queries finding the data they need to modify, this isn’t painful.
Just be wary of:
Triggers
Foreign keys
Indexed views
Which can make life more interesting than most people care to deal with.
Now I know, a couple posts ago I told you that there’s very little benefit to error/transaction handling if you’re not going to do anything with them — and that I’ve left that out of this pseudo code — you’ll just have to forgive me my transgression here.
I had to save something for tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.