Active Blooper
Remember yesterday? Yeah, me either. But I do have access to yesterday’s blog post, so I can at least remember that.
What a post that was.
We talked about filtered indexes, some of the need-to-know points, when to use them, and then a sad shortcoming.
Today we’re going to talk about how to overcome that shortcoming, but… there’s stuff you need to know about these things, too.
We’re gonna start off with some Deja Vu!
First, there are some session-level settings that need to be appropriately applied for them to be considered by the optimizer. This is especially important if you’re putting any logic into a SQL Server Agent job, because it uses the wrong settings for some reason.
Here are the correct settings:
- QUOTED_IDENTIFIER ON
- ANSI_NULLS ON
- ANSI_PADDING ON
- ANSI_WARNINGS ON
- ARITHABORT ON
- CONCAT_NULL_YIELDS_NULL ON
- NUMERIC_ROUNDABORT OFF
Second, computed columns are sort of like regular columns: you can only search them efficiently if you index them.
This may come as a surprise to you, but indexes put data in order so that it’s easier to find things in them.
The second thing you should know about the second thing here is that you don’t need to persist computed columns to add an index to them, or to get statistics generated for the computed values (but there are some rules we’ll talk about later).
For example, let’s say you do this:
ALTER TABLE dbo.Users ADD TotalVotes AS (UpVotes + DownVotes); CREATE INDEX u ON dbo.Users (TotalVotes) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
The index gets created just fine. This is incredibly handy if you need to add a computed column to a large table, because there won’t be any blocking while adding the column. The index is another matter, depending on if you’re using Enterprise Edition.
Third, SQL Server is picky about them, kind of. The problem is a part of the query optimization process called expression matching that… matches… expressions.
For example, these two queries both have expressions in them that normally wouldn’t be SARGable — meaning you couldn’t search a normal index on (Upvotes, Downvotes) efficiently.
But because we have an indexed computed column, one of them gets a magic power, and the other one doesn’t.
Because it’s backwards.
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE (u.UpVotes + u.DownVotes) > 1000; SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE (u.DownVotes + u.UpVotes) > 1000;

See what happens when you confuse SQL Server?
If you have full control of the code, it’s probably safer to reference the computed column directly rather than rely on expression matching, but expression matching can be really useful when you can’t change the code.
Fourth, don’t you ever ever never ever ever stick a scalar UDF in a computed column or check constraint. Let’s see what happens:
CREATE FUNCTION dbo.suck(@Upvotes int, @Downvotes int)
RETURNS int
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
RETURN (SELECT @Upvotes + @Downvotes);
END;
GO
ALTER TABLE dbo.Users ADD TotalVotes AS dbo.suck(UpVotes, DownVotes);
CREATE INDEX u ON dbo.Users (TotalVotes) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE (u.DownVotes + u.UpVotes) > 1000;
Remember that this is the query that has things backwards and doesn’t use the index on our computed column, but look what happened to the query plan:
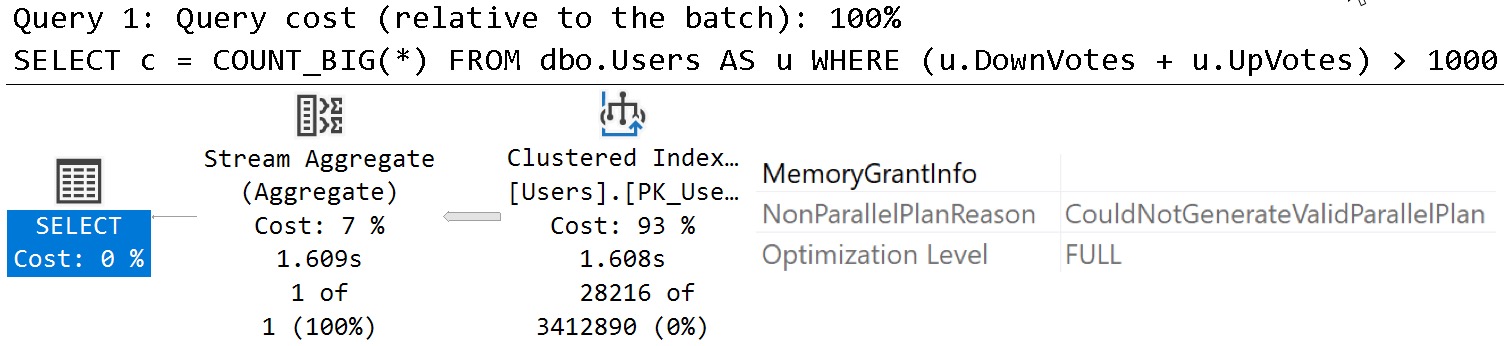
Querying a completely different index results in a plan that SQL Server can’t parallelize because of the function.
Things that won’t fix this:
- SQL Server 2019 scalar UDF inlining
- Persisting the computed column
- Using a different kind of T-SQL function; you can’t use them in computed columns
Things that might fix this:
- Follow the answers here
Fifth: Column store indexes are weird with them. There’s an odd bit of a matrix, too.
- Anything before SQL Server 2017, no dice
- Any nonclustered columnstore index through SQL Server 2019, no dice
- For 2017 and 2019, you can create a clustered columnstore index on a table with a computed column as long as it’s not persisted
--Works CREATE TABLE clustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date)); CREATE CLUSTERED COLUMNSTORE INDEX c ON dbo.clustered_columnstore; --Doesn't work CREATE TABLE nonclustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date)); CREATE NONCLUSTERED COLUMNSTORE INDEX n ON dbo.nonclustered_columnstore(id, some_date, next_date, diff_date); --Clean! DROP TABLE dbo.clustered_columnstore, dbo.nonclustered_columnstore; --Doesn't work, but throws a misleading error CREATE TABLE clustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date) PERSISTED); CREATE CLUSTERED COLUMNSTORE INDEX c ON dbo.clustered_columnstore; --Still doesn't work CREATE TABLE nonclustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date) PERSISTED); CREATE NONCLUSTERED COLUMNSTORE INDEX n ON dbo.nonclustered_columnstore(id, some_date, next_date, diff_date); --Clean! DROP TABLE dbo.clustered_columnstore, dbo.nonclustered_columnstore;
General Uses
The most general use for computed columns is to materialize an expression that a query has to filter on, but that wouldn’t otherwise be able to take advantage of an index to locate rows efficiently, like the UpVotes and DownVotes example above.
Even with an index on UpVotes, DownVotes, nothing in your index keeps track of what row values added together would be.
SQL Server has to do that math every time the query runs and then filter on the result. Sometimes those expressions can be pushed to an index scan, and other times they need a Filter operator later in the plan.
Consider a query that inadvisably does one of these things:
- function(column) = something
- column + column = something
- column + value = something
- value + column = something
- column = case when …
- value = case when column…
- convert_implicit(column) = something
As long as all values are known ahead of time — meaning they’re not a parameter, variable, or runtime constant like GETDATE() — you can create computed columns that you can index and make searches really fast.
Take this query and index as an example:
SELECT c = COUNT_BIG(*) FROM dbo.Posts AS p WHERE DATEDIFF(YEAR, p.CreationDate, p.LastActivityDate) > 9;
CREATE INDEX p ON dbo.Posts(CreationDate, LastActivityDate) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
The best we can do is still to read every row via a scan:

But we can fix that by computing and indexing:
ALTER TABLE dbo.Posts ADD ComputedDiff AS DATEDIFF(YEAR, CreationDate, LastActivityDate);
CREATE INDEX p ON dbo.Posts(ComputedDiff) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE, DROP_EXISTING = ON);
And now our query plan is much faster, without needing to go parallel, or more parallel, to get faster:

SQL Server barely needs to flinch to finish that query, and we get an actually good estimate to boot.
Crappy Limitations
While many computed columns can be created, not all can be indexed. For example, something like this would be lovely to have and to have indexed:
ALTER TABLE dbo.Users ADD RecentUsers AS DATEDIFF(DAY, LastAccessDate, SYSDATETIME()); CREATE INDEX u ON dbo.Users (RecentUsers);
While the column creation does succeed, the index creation failed:
Msg 2729, Level 16, State 1, Line 177
Column ‘RecentUsers’ in table ‘dbo.Users’ cannot be used in an index or statistics or as a partition key because it is non-deterministic.
You also can’t reach out to other tables:
ALTER TABLE dbo.Users ADD HasABadge AS CASE WHEN EXISTS (SELECT 1/0 FROM dbo.Badges AS b WHERE b.UserId = Id) THEN 1 ELSE 0 END;
SQL Server doesn’t like that:
Msg 1046, Level 15, State 1, Line 183
Subqueries are not allowed in this context. Only scalar expressions are allowed.
There are other, however these are the most common disappointments I come across.
Some of the things that computed columns fall flat with are things we can remedy with indexed views, but boy howdy are there a lot of gotchas.
We’ll talk about those tomorrow!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.