Back To Business
I think I have probably spent 500 hours of my life rewriting T-SQL Scalar UDFs to avoid all the performance problems associated with them.
The obvious choice is the Inline Table Valued Function, which has fewer performance issues baked in. For the kids out there: they don’t spill trauma.
But getting the rewrite right can be tricky, especially when it’s possible for the function to return NULL values.
I’m going to walk through a simple example, and show you how to get the results you want, without adding abusing your developers.
What is not covered in this post are all the performance issues caused by UDFs. If you want to get into that, click the training link at the bottom of this post.
The Problem
Here’s the function we need to rewrite. It returns a simple bit value if a particular user was active after a certain date:
CREATE OR ALTER FUNCTION
dbo.rewrite
(
@UserId int,
@LastAccessDate datetime
)
RETURNS bit
AS
BEGIN
DECLARE
@b bit = 0,
@d datetime = GETDATE(); /*NOFROID4U*/
SELECT
@b =
CASE
WHEN u.Id IS NOT NULL
THEN 1
ELSE 0
END
FROM dbo.Users AS u
WHERE u.Id = @UserId
AND u.LastAccessDate > @LastAccessDate;
RETURN
@b;
END;
GO
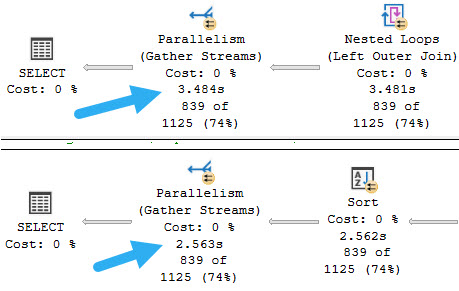
Since I’m using SQL Server 2022 in compatibility level 160, I’m declaring a useless datetime parameter and using GETDATE() to set it to a value to avoid scalar UDF inlining.
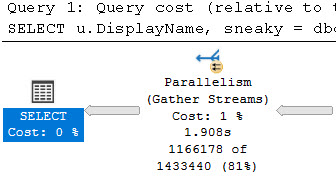
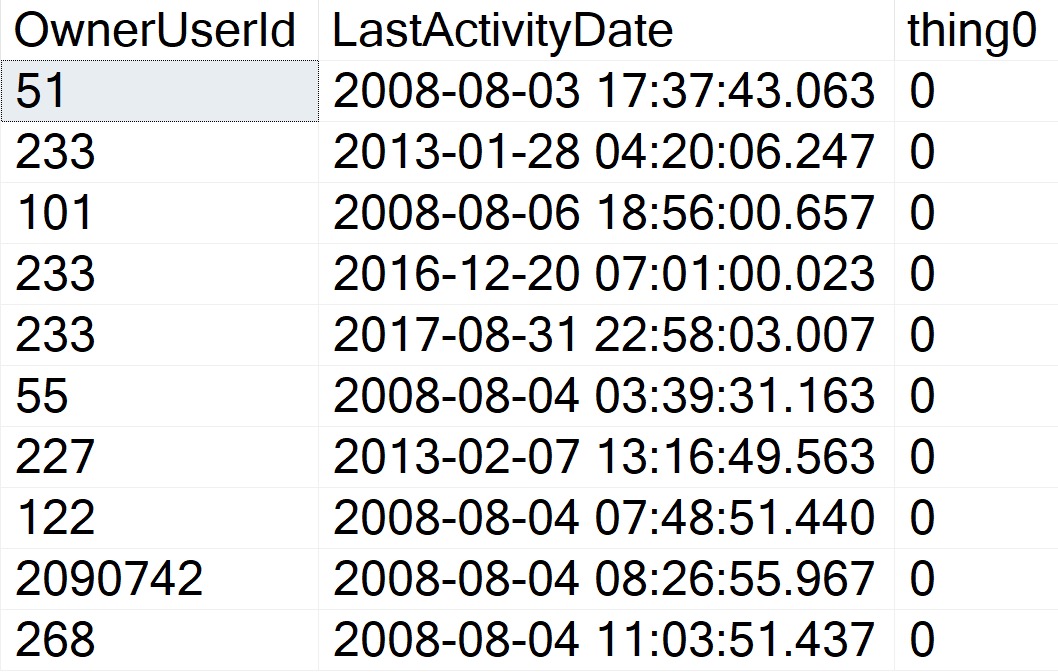
We can call it about like so (again, this query is too trivial to suffer any performance issues), and get some reasonable-looking results back.
SELECT TOP (10)
p.OwnerUserId,
p.LastActivityDate,
thing0 =
dbo.rewrite
(
p.OwnerUserId,
GETDATE()
)
FROM dbo.Posts AS p
WHERE p.Score = 1;
Writeable Media
Rewriting this function looks straightforward. All we need to do is Robocop a few parts and pieces and badabing badaboom we’re done.
Note that to really complete this, we’d also need to add a convert to bit to avoid SQL Server implicitly converting the output of the case expression to a (potentially) different datatype, but we’ll fix that in the final rewrite.
CREATE OR ALTER FUNCTION
dbo.the_rewrite
(
@UserId int,
@LastAccessDate datetime
)
RETURNS table
WITH SCHEMABINDING
AS
RETURN
SELECT
b =
CASE
WHEN u.Id IS NOT NULL
THEN 1
ELSE 0
END
FROM dbo.Users AS u
WHERE u.Id = @UserId
AND u.LastAccessDate > @LastAccessDate;
GO
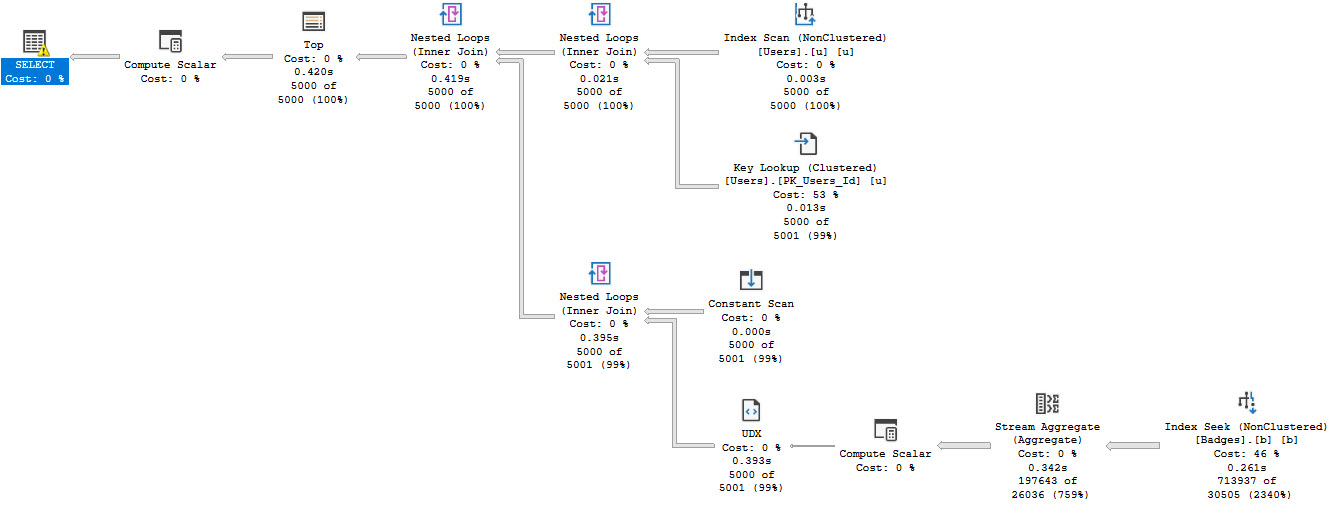
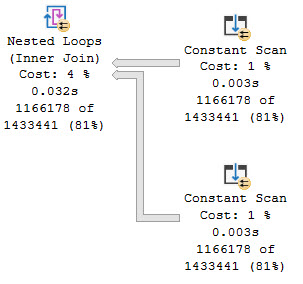
Of course, this alters how we need to reference the function in the calling query. Inline table valued functions are totally different types of objects from scalar UDFs.
SELECT TOP (10)
p.OwnerUserId,
p.LastActivityDate,
thing1 =
(
SELECT
t.b
FROM dbo.the_rewrite
(
p.OwnerUserId,
GETDATE()
) AS t
)
FROM dbo.Posts AS p
WHERE p.Score = 1;
But the results are disappointing! Where we once had perfectly formed zeroes, now we have a bunch of NULLs that severely harsh our mellow.
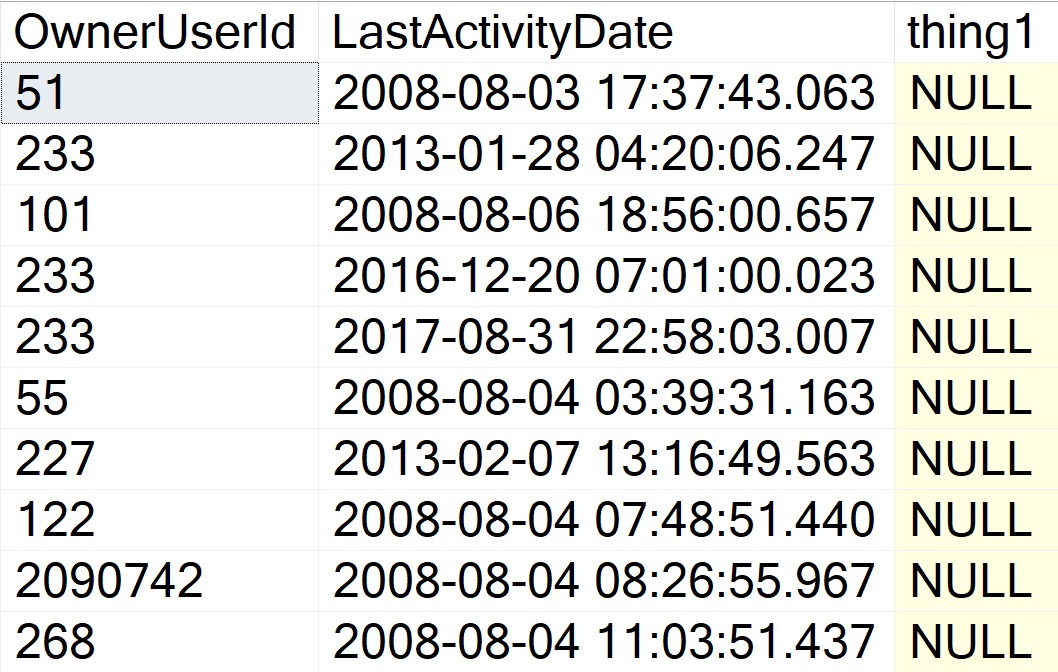
This can obviously cause problems for whomever or whatever is ingesting the result set.
- Expectations: 1 or 0
- Reality: NULL
Shame, that.
Changing The Query
Many developers will attempt something like this first, to replace NULLs in the calling query:
SELECT TOP (10)
p.OwnerUserId,
p.LastActivityDate,
thing1 =
(
SELECT
ISNULL
(
t.b,
0
)
FROM dbo.the_rewrite
(
p.OwnerUserId,
GETDATE()
) AS t
)
FROM dbo.Posts AS p
WHERE p.Score = 1;
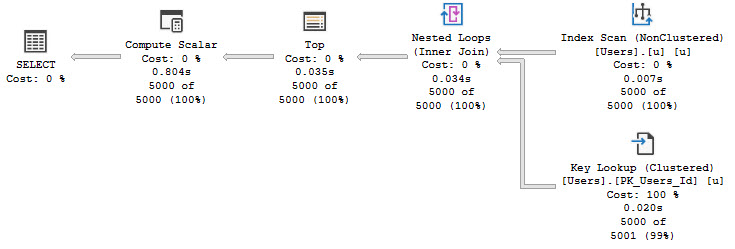
But this will still produce NULL realities where we have zeroed expectations. We could take a step way back and do something like this:
SELECT TOP (10)
p.OwnerUserId,
p.LastActivityDate,
thing1 =
ISNULL
(
(
SELECT
t.b
FROM dbo.the_rewrite
(
p.OwnerUserId,
GETDATE()
) AS t
),
0
)
FROM dbo.Posts AS p
WHERE p.Score = 1;
GO
But this is an ugly and annoying thing to remember. Imagine having to explain this to someone reading or trying to incorporate our beautiful new function into a query.
We should fix this inside the function.
Fixer Upper
I’m not going to pretend this is the only way to do this. You can likely figure out half a million ways to pet this cat. It’s just easy.
CREATE OR ALTER FUNCTION
dbo.the_inner_rewrite
(
@UserId int,
@LastAccessDate datetime
)
RETURNS table
WITH SCHEMABINDING
AS
RETURN
SELECT
b =
CONVERT
(
bit,
MAX(x.b)
)
FROM
(
SELECT
b =
CASE
WHEN u.Id IS NOT NULL
THEN 1
ELSE 0
END
FROM dbo.Users AS u
WHERE u.Id = @UserId
AND u.LastAccessDate > @LastAccessDate
UNION ALL
SELECT
b = 0
) AS x;
GO
We have:
- Our original query, which may return 1 or 0 based on existence
- A union all to a zero literal so that a result is guaranteed to be produced
- An outer max to get the higher value between the two inner selects
And this will produce expected results, with the final output converted to a bit.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.