You’ve Got No Security
Despite being a bouncer for many years, I have no interest at all in security.
Users, logins, roles, grant, deny. Not for me. I’ve seen those posters, and they’re terrifying.
Gimme 3000 lines of dynamic SQL any day.
This is a slightly different take on yesterday’s post, which is also a common problem I see in queries today.
Someone wrote a function to figure out if a user is trusted, or has the right permissions, and sticks it in a predicate — it could be a join or where clause.
High Finance
Stack Overflow isn’t exactly a big four accounting firm, but for some reason big four accounting firms don’t make their databases public under Creative Commons licensing.
So uh. Here we are.
And here’s our query.
DECLARE @UserId INT = 22656, --2788872, 22656
@SQL NVARCHAR(MAX) = N'';
SET @SQL = @SQL + N'
SELECT p.Id,
p.AcceptedAnswerId,
p.AnswerCount,
p.CommentCount,
p.CreationDate,
p.FavoriteCount,
p.LastActivityDate,
p.OwnerUserId,
p.Score,
p.ViewCount,
v.BountyAmount,
c.Score
FROM dbo.Posts AS p
LEFT JOIN dbo.Votes AS v
ON p.Id = v.PostId
AND dbo.isTrusted(@iUserId) = 1
LEFT JOIN dbo.Comments AS c
ON p.Id = c.PostId
WHERE p.PostTypeId = 5;
';
EXEC sys.sp_executesql @SQL,
N'@iUserId INT',
@iUserId = @UserId;
There’s a function in that join to the Votes table. This is what it looks like.
CREATE OR ALTER FUNCTION dbo.isTrusted ( @UserId INT )
RETURNS BIT
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @Bitty BIT;
SELECT @Bitty = CASE WHEN u.Reputation >= 10000
THEN 1
ELSE 0
END
FROM dbo.Users AS u
WHERE u.Id = @UserId;
RETURN @Bitty;
END;
GO
Bankrupt
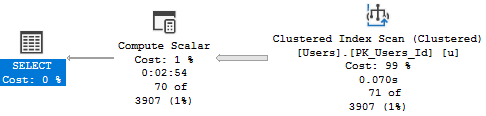
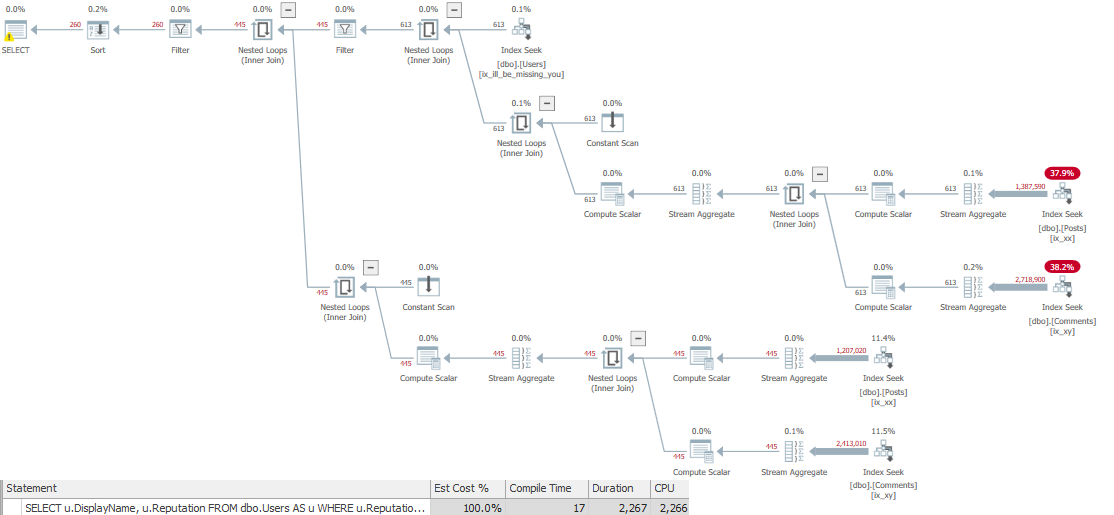
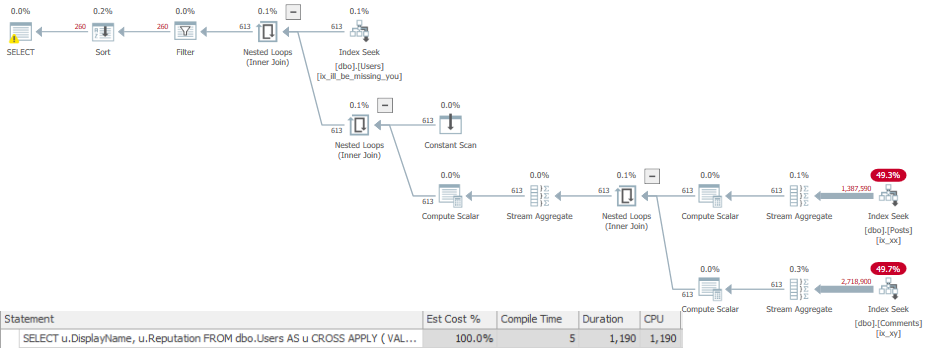
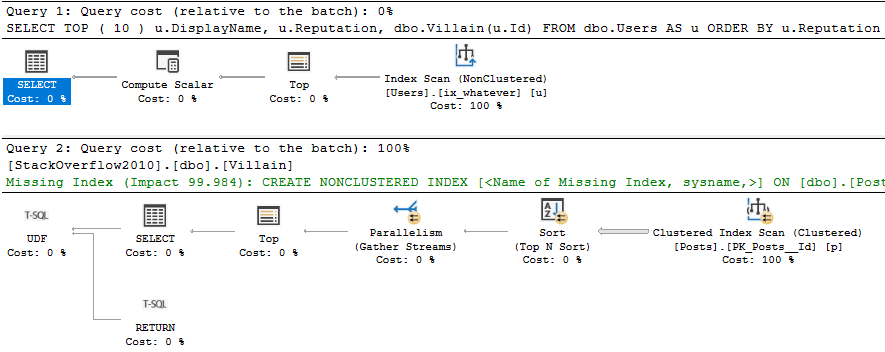
There’s not a lot of importance in the indexes, query plans, or reads.
What’s great about this is that you don’t need to do a lot of analysis — we can look purely at runtimes.
It also doesn’t matter if we run the query for a trusted (22656) or untrusted (2788872) user.
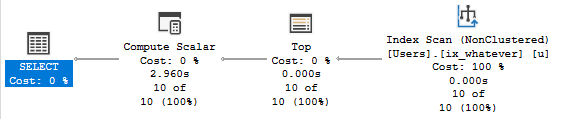
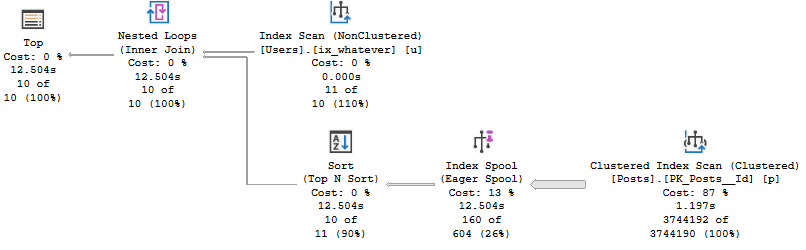
In compat level 140, the runtimes look like this:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 140;
SQL Server Execution Times:
CPU time = 7219 ms, elapsed time = 9925 ms.
SQL Server Execution Times:
CPU time = 7234 ms, elapsed time = 9903 ms.
In compat level 150, the runtimes look like this:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
SQL Server Execution Times:
CPU time = 2734 ms, elapsed time = 781 ms.
SQL Server Execution Times:
CPU time = 188 ms, elapsed time = 142 ms.
In both runs, the trusted user is first, and the untrusted user is second.
Sure, the trusted user query ran half a second longer, but that’s because it actually had to produce data in the join.
One important thing to note is that the query was able to take advantage of parallelism when it should have (CPU time is higher than elapsed time).
In older versions (or even lower compat levels), scalar valued functions would inhibit parallelism. Now they don’t when they’re inlined.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.