Reusable Logic
In most programming languages, it’s quite sensible to create a variable or parameter, use some predefined logic to assign it a value, and then keep reusing it to prevent having to execute the same code over and over again.
But those languages are all procedural, and have a bit of a different set of rules and whatnot. In SQL Server, there are certainly somewhat procedural elements.
- Functions
- Control-flow logic
- Cursors
- While loops
- Maybe the inner side of Nested Loops joins
You may be able to name some more, if you really get to thinking about it. That should be a common enough list, though.
Reusable Problems
SQL Server has a wonderful optimizer. It’s capable of many things, but it also has some problems.
Many of those problems exist today for “backwards compatibility”. In other words: play legacy games, win legacy performance.
Lots of people have found “workarounds” that rely on exploiting product behavior, and taking that away or changing it would result in… something else.
That’s why so many changes (improvements?) are hidden behind trace flags, compatibility levels, hints, batch mode, and other “fences” that you have to specifically hop to see if the grass is greener.
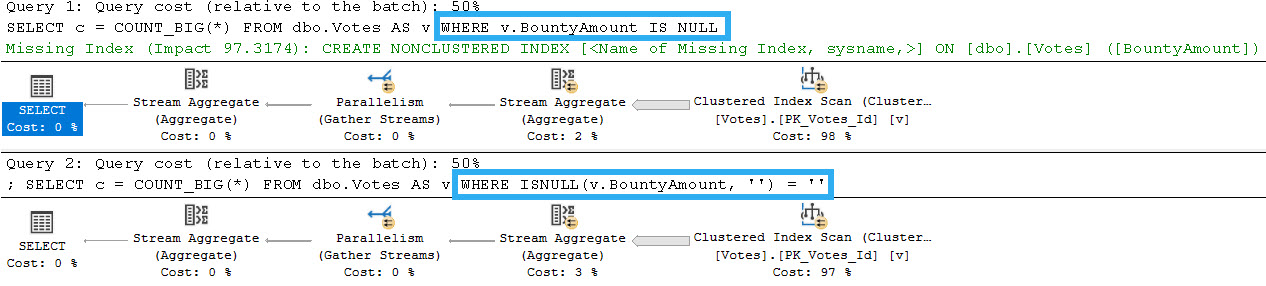
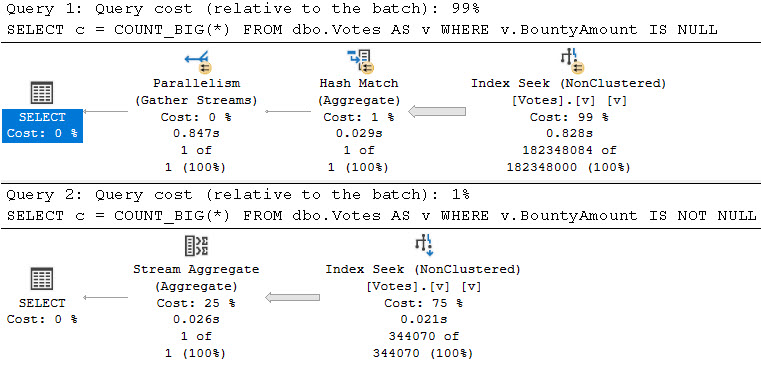
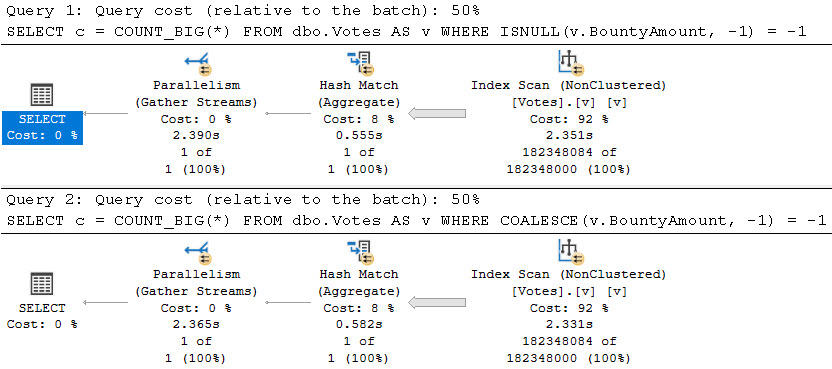
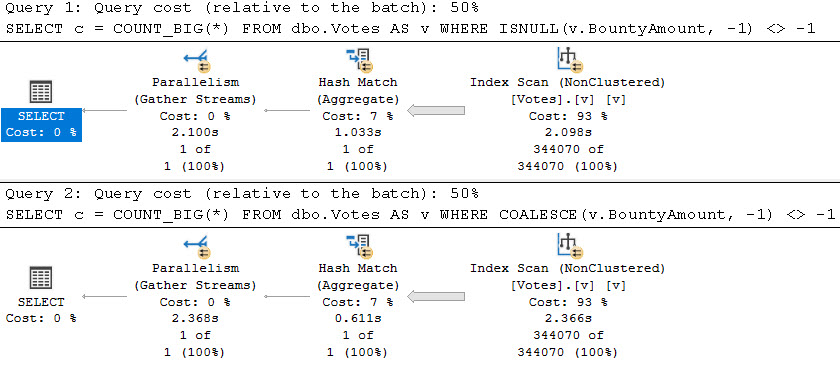
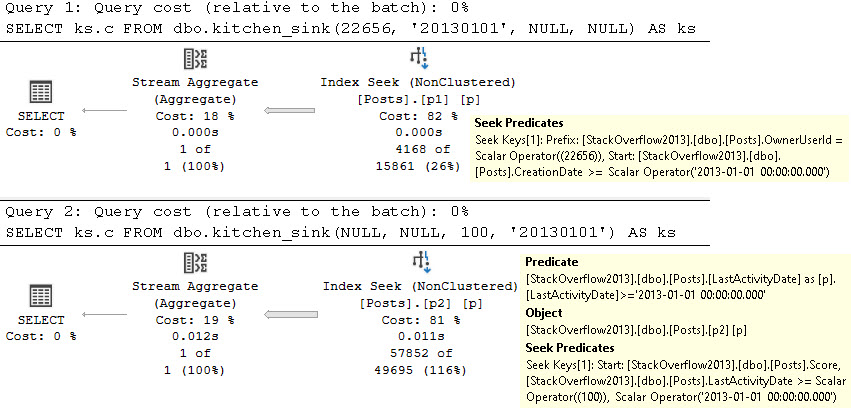
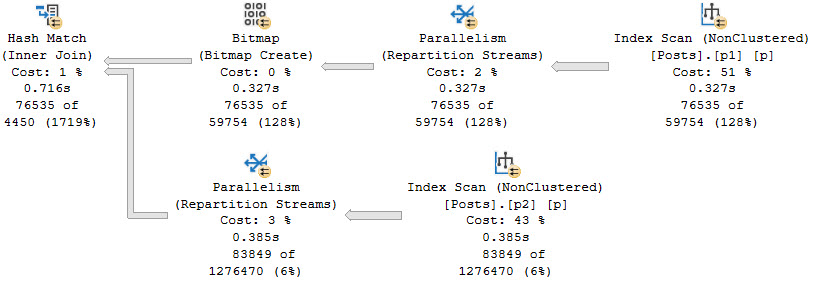
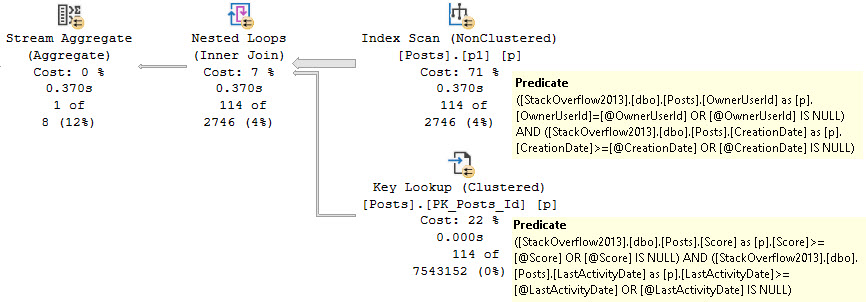
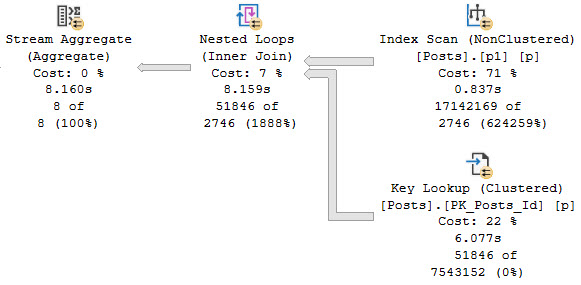
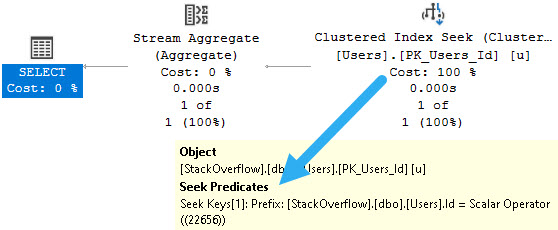
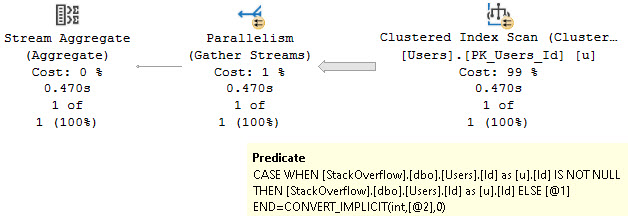
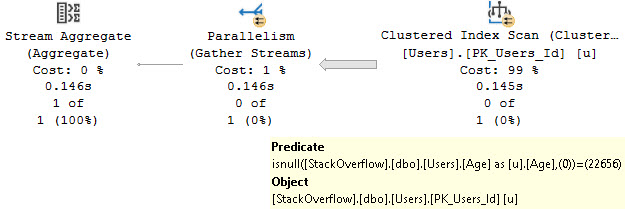
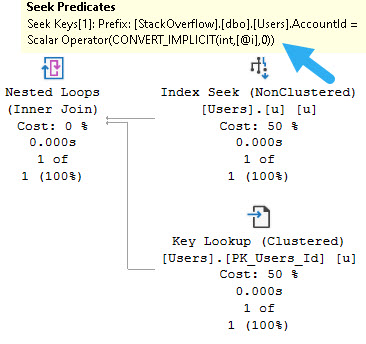
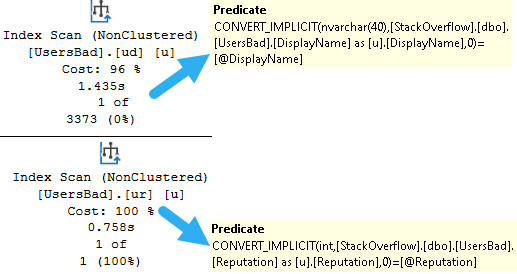
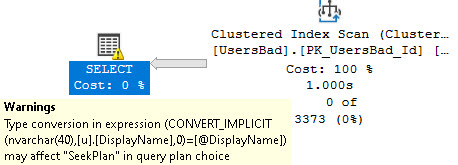
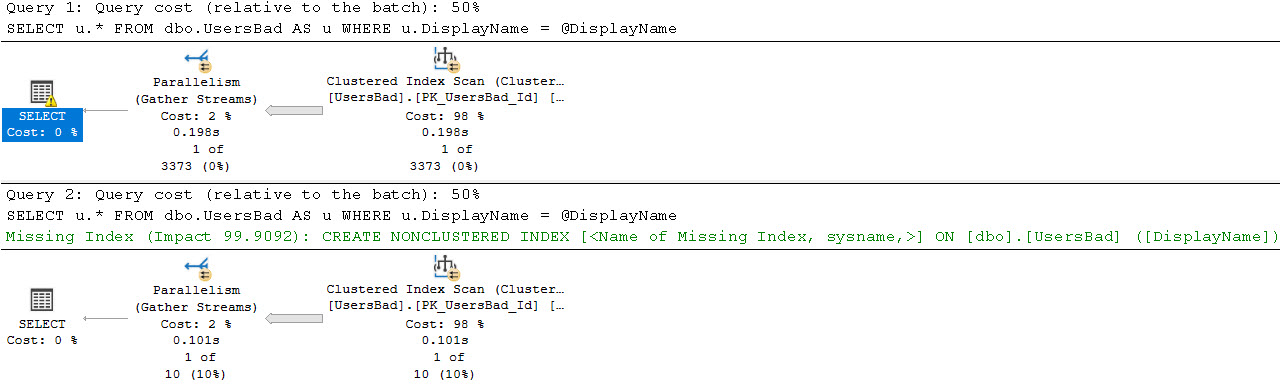
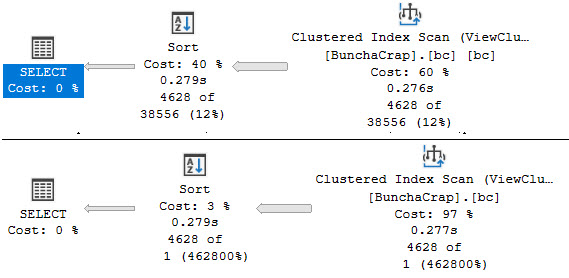
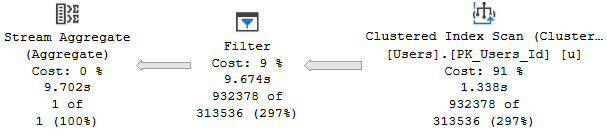
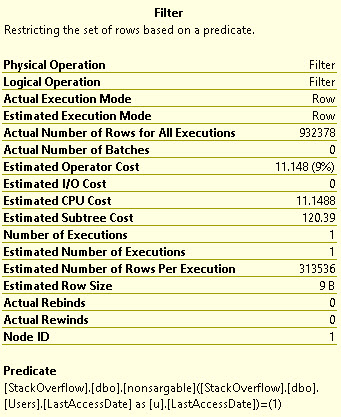
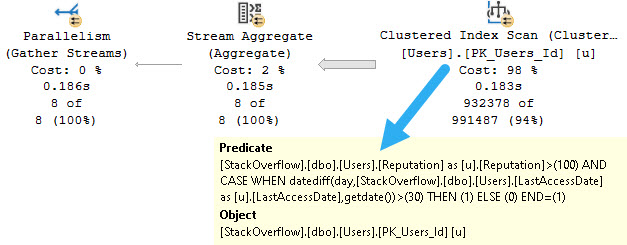
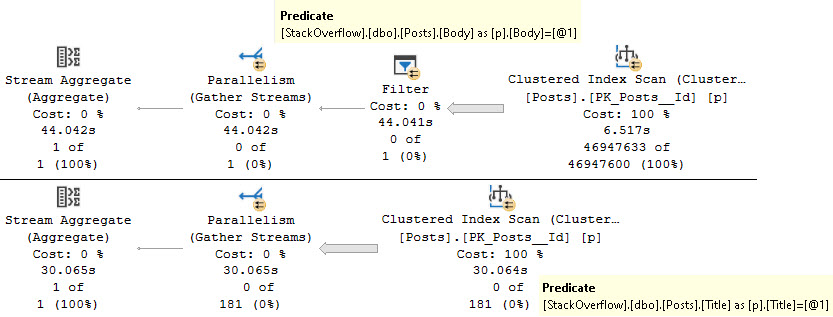
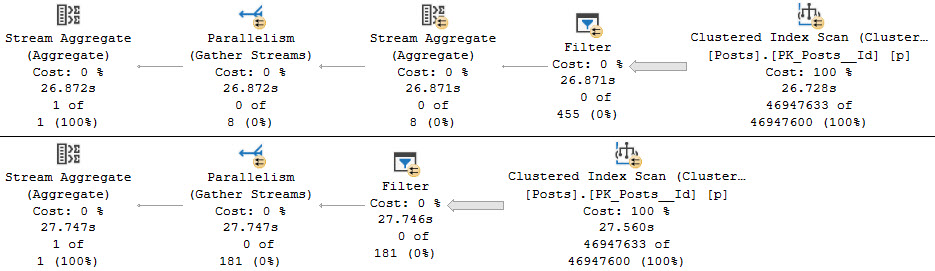
One of those things is the use of local variables. The linked post details how lousy those can be.
In this post, I show how you’re better off using the date math expressions instead.
And in this post, I show how you’re better off doing date math on parameters rather than on columns.
Let’s bring all that together!
Reusable Solutions
In SQL Server, context is everything. By context, I mean the way different methods of query execution are able to accept arguments from others.
You’ll sometimes hear this referred to as scope, too. Usually people will say inner context/scope and outer context/scope, or something similar.
What that means is something like this, if we’re talking about stored procedures:
CREATE PROCEDURE
dbo.InnerContext
(
@StartDate datetime,
@EndDate datetime
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
C.PostId,
Score =
SUM(C.Score)
FROM dbo.Comments AS C
JOIN dbo.Votes AS V
ON C.PostId = V.PostId
WHERE C.CreationDate >= @StartDate
AND c.CreationDate < @EndDate
GROUP BY c.PostId;
END;
GO
CREATE PROCEDURE
dbo.OuterContext
(
@StartDate datetime,
@EndDate datetime
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @StartDate IS NULL
BEGIN
SELECT
@StartDate = GETDATE();
END;
IF @EndDate IS NULL
BEGIN
SELECT
@EndDate = DATEADD(DAY, 30, GETDATE());
END;
EXEC dbo.InnerContext
@StartDate = @StartDate,
@EndDate = @EndDate;
END;
If you’re okay using dynamic SQL, and really, you should be because it’s awesome when you’re not bad at it, you can do something like this:
CREATE PROCEDURE
dbo.OuterContext
(
@StartDate datetime,
@EndDate datetime
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @StartDate IS NULL
BEGIN
SELECT
@StartDate = GETDATE();
END;
IF @EndDate IS NULL
BEGIN
SELECT
@EndDate = DATEADD(DAY, 30, GETDATE());
END;
DECLARE
@sql nvarchar(MAX) = N'
/*dbo.OuterContext*/
SELECT
C.PostId,
Score =
SUM(C.Score)
FROM dbo.Comments AS C
JOIN dbo.Votes AS V
ON C.PostId = V.PostId
WHERE C.CreationDate >= @StartDate
AND c.CreationDate < @EndDate
GROUP BY c.PostId;
';
EXEC sys.sp_executesql
@sql,
N'@StartDate datetime,
@EndDate datetime',
@StartDate,
@EndDate;
END;
Which will achieve the same thing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.