Finger On It
All good things must come to an end. When I started this series, I wasn’t entirely sure where that would be.
Turns out, seven weeks about covers all the major stuff I see regularly when working with clients.
And this is just the code and indexes; it doesn’t even start on the SQL Server settings, maintenance practices, table design, and hardware configurations I see getting in the way.
Perhaps there is a part 2, but I’m going to let this stand for now.
- Software Vendor Mistakes With SQL Server: Not Strongly Typing Parameters
- Software Vendor Mistakes With SQL Server: Not Parameterizing Queries
- Software Vendor Mistakes With SQL Server: Sticking With ORMs Only
- Software Vendor Mistakes With SQL Server: Passing Long IN Clauses To Queries From An ORM
- Software Vendor Mistakes With SQL Server: Selecting Everything From Everywhere
- Software Vendor Mistakes With SQL Server: Mistaking NOLOCK For Concurrency
- Software Vendor Mistakes With SQL Server: Not Using An Optimistic Isolation Level
- Software Vendor Mistakes With SQL Server: Modifying Millions of Rows At A Time
- Software Vendor Mistakes With SQL Server: Explicit And Implicit Transactions
- Software Vendor Mistakes With SQL Server: Not Using Computed Columns
- Software Vendor Mistakes With SQL Server: Using Scalar UDFs In Computed Columns Or Check Constraints
- Software Vendor Mistakes With SQL Server: Using MAX Datatypes Unnecessarily
- Software Vendor Mistakes With SQL Server: Using Integers Instead Of Big Integers For Identity Columns
- Software Vendor Mistakes With SQL Server: Overly Complicated Triggers
- Software Vendor Mistakes With SQL Server: Not Letting Customers Add Indexes
- Software Vendor Mistakes With SQL Server: Not Cleaning Up Old Indexes
- Software Vendor Mistakes With SQL Server: Not Deduplicating Overlapping Indexes
- Software Vendor Mistakes With SQL Server: Not Indexing For Evolving Queries
- Software Vendor Mistakes With SQL Server: Avoiding Clustered Indexes
- Software Vendor Mistakes With SQL Server: Designing Nonclustered Indexes Poorly
- Software Vendor Mistakes With SQL Server: Not Using Filtered Indexes Or Indexed Views
- Software Vendor Mistakes With SQL Server: Lowering Fill Factor For Every Index
- Software Vendor Mistakes With SQL Server: Thinking Index Rebuilds Solve Every Problem
- Software Vendor Mistakes With SQL Server: Not Taking Advantage Of Index Compression
- Software Vendor Mistakes With SQL Server: Misusing @Table Variables
- Software Vendor Mistakes With SQL Server: Not Using #Temp Tables
- Software Vendor Mistakes With SQL Server: Not Getting Parallel Inserts Into #Temp Tables
- Software Vendor Mistakes With SQL Server: Indexing #Temp Tables Incorrectly
- Software Vendor Mistakes With SQL Server: Misusing Common Table Expressions
- Software Vendor Mistakes With SQL Server: Scalar User Defined Functions
- Software Vendor Mistakes With SQL Server: Multi Statement Table Valued Functions
- Software Vendor Mistakes With SQL Server: Not Using Inline Table Valued Functions
- Software Vendor Mistakes With SQL Server: Writing Functions That Already Exist
- Software Vendor Mistakes With SQL Server: String Splitting With Functions
- Software Vendor Mistakes With SQL Server: Using Functions In Join Or Where Clauses
- Software Vendor Mistakes With SQL Server: Using Date Functions On Columns Or Local Variables
- Software Vendor Mistakes With SQL Server: Joining On OR Conditions
- Software Vendor Mistakes With SQL Server: Using Left Joins To Find Rows That Don’t Exist
- Software Vendor Mistakes With SQL Server: Using CASE Expressions In JOIN Or WHERE Clauses
- Software Vendor Mistakes With SQL Server: IF Branching In Stored Procedures
- Software Vendor Mistakes With SQL Server: Writing Unsafe Dynamic SQL
- Software Vendor Mistakes With SQL Server: Handling Optional Parameters
- Software Vendor Mistakes With SQL Server: Writing And Optimizing Paging Queries
- Software Vendor Mistakes With SQL Server: Dealing With Bad Parameter Sniffing
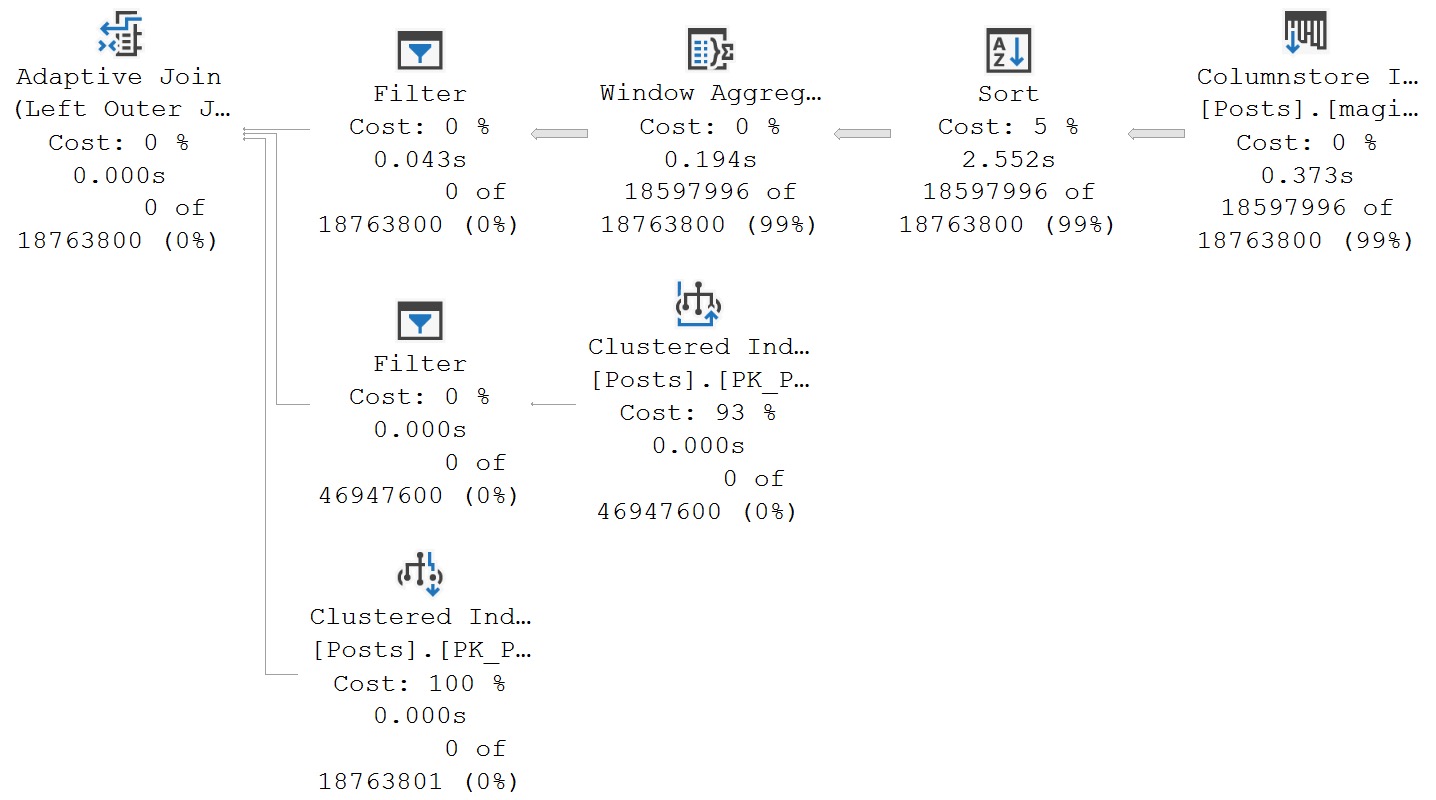
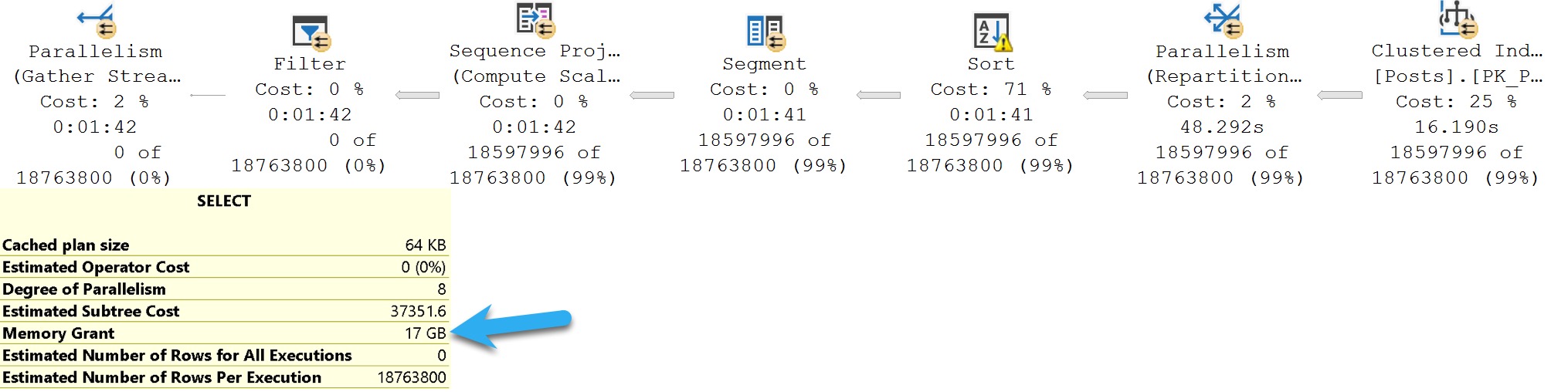
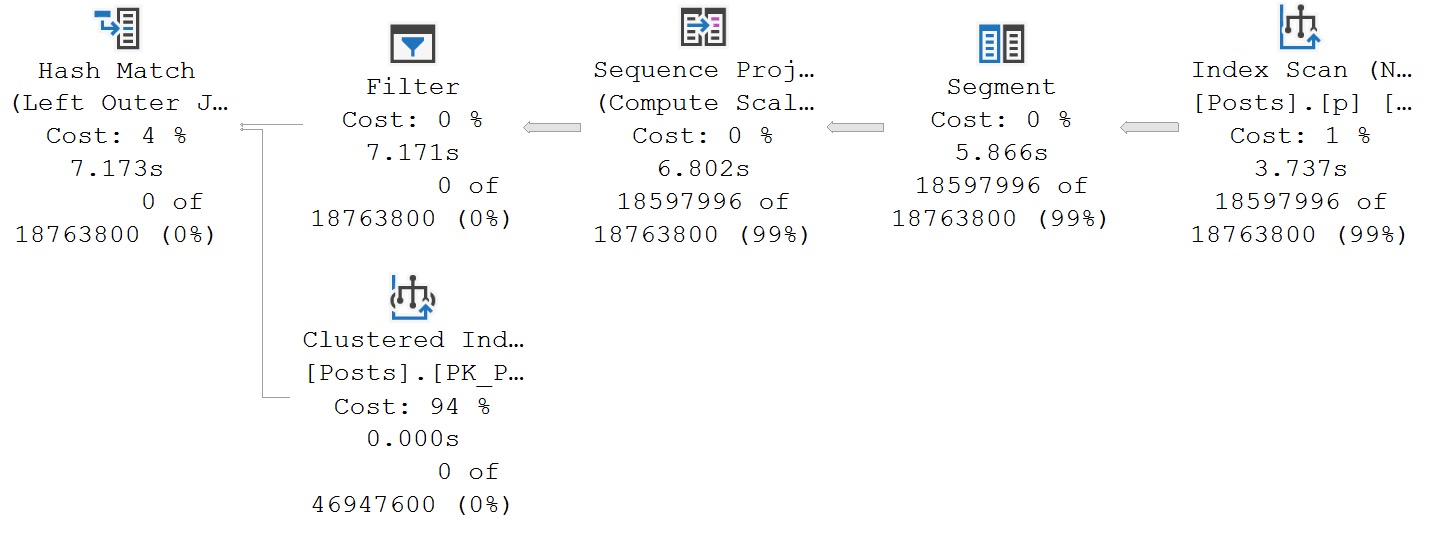
- Software Vendor Mistakes With SQL Server: Not Indexing For Windowing Functions
- Software Vendor Mistakes With SQL Server: Not Using Batch Mode
- Software Vendor Mistakes With SQL Server: Not Enforcing Code Consistency
- Software Vendor Mistakes With SQL Server: Not Enforcing Code Formatting
Happy clicking! Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.