You’re Short
I ran across something similar in a previous post: Index Spools When You Have An Index.
But here we are again, with the optimizer treating us like fools for our index choices.
Let’s say we have this index on the Comments table:
CREATE INDEX lol
ON dbo.Comments
(UserId)
INCLUDE
(Id, PostId, Score, CreationDate, Text);
Is it a great idea? I dunno. But it’s there, and it should make things okay for this query:
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0;
You’re Round
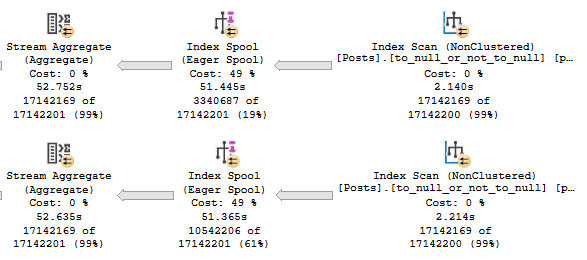
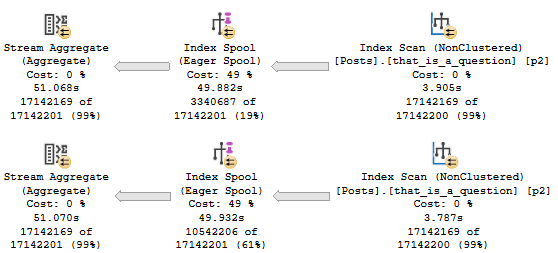
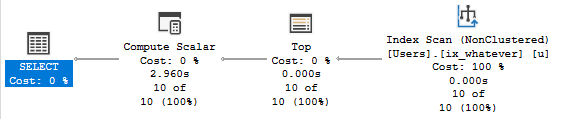
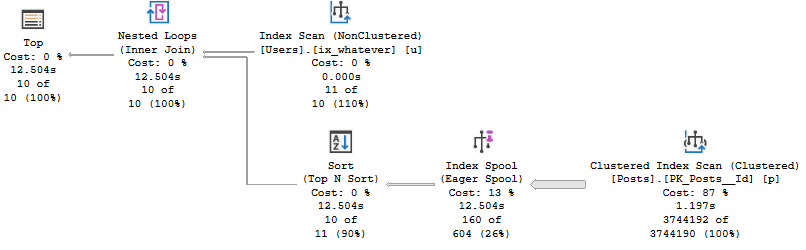
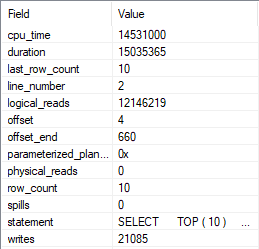
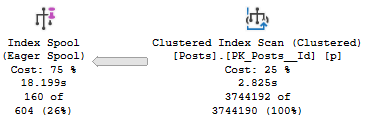
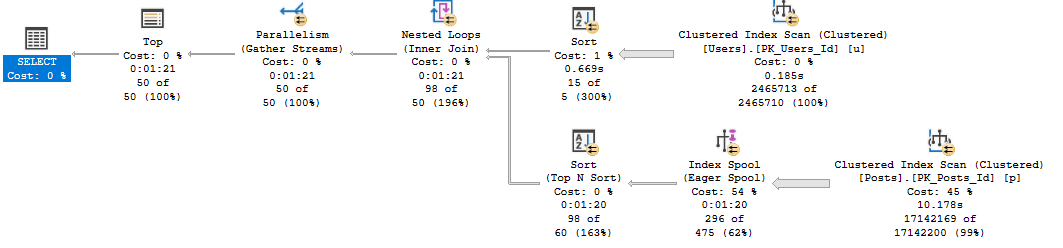
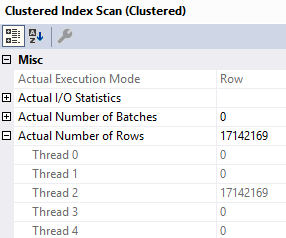
But when we run the query and collect the plan, something rather astounding happens.
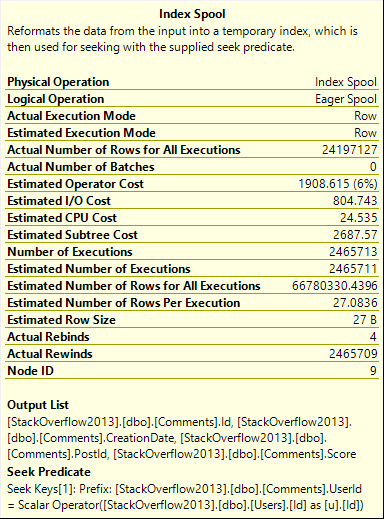
The optimizer uses our index to build a smaller index!
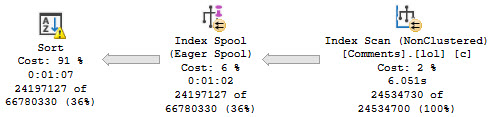
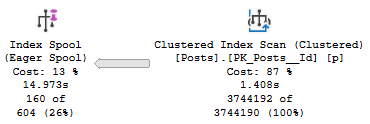
Digging in on the Eager Index Spool, it’s a nearly identical copy of the index we have, just without the Text column.
Your Mother Dresses You Funny
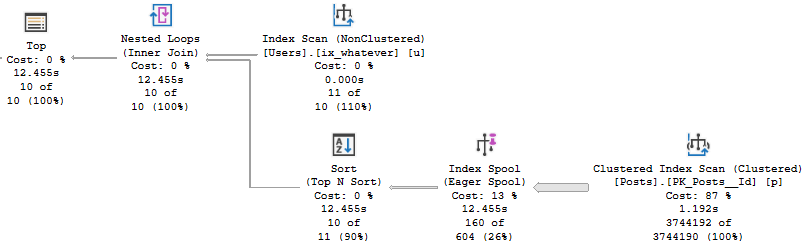
Of course, the optimizer being the unreasonable curmudgeon that it is, the only workaround is to also create the more narrow index.
CREATE INDEX lmao
ON dbo.Comments
(UserId)
INCLUDE
(Id, PostId, Score, CreationDate);
Or add the Text column to the select:
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate,
ca.Text
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate,
c.Text
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0;
But that has a weird side effect, too. We’ll look at that tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.