Repetition Is Everything
I know what you’re thinking: this is another post that asks for a hint to materialize CTEs.
You’re wrong. I don’t want another hint that I can’t add to queries to solve a problem because the code is coming from a vendor or ORM.
No, I want the optimizer to smarten up about this sort of thing, detect CTE re-use, and use one of the New And Improved Spools™ to cache results.
Let’s take a look at where this would come in handy.
Standalone
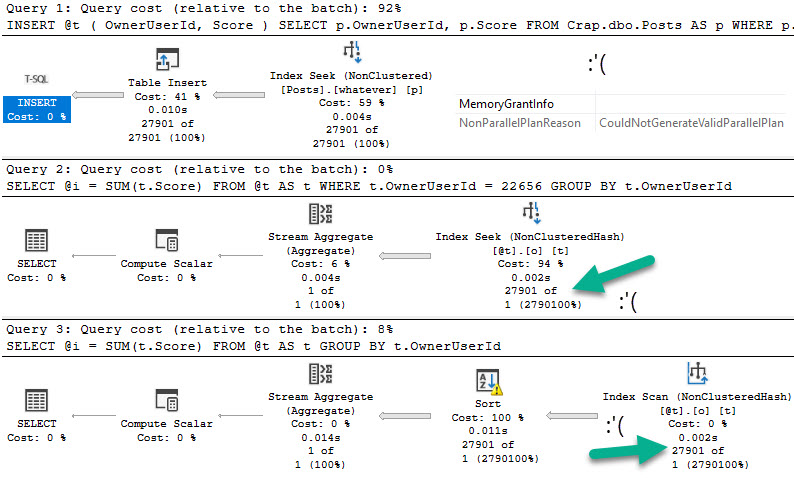
If we take this query by itself and look at the execution plan, it conveniently shows one access of Posts and Users, and a single join between the two.
SELECT
u.Id AS UserId,
u.DisplayName,
p.Id AS PostId,
p.AcceptedAnswerId,
TotalScore =
SUM(p.Score)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE u.Reputation > 100000
GROUP BY
u.Id,
u.DisplayName,
p.Id,
p.AcceptedAnswerId
HAVING SUM(p.Score) > 1

Now, let’s go MAKE THINGS MORE READABLE!!!
Ality
WITH spool_me AS
(
SELECT
u.Id AS UserId,
u.DisplayName,
p.Id AS PostId,
p.AcceptedAnswerId,
TotalScore =
SUM(p.Score)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE u.Reputation > 100000
GROUP BY
u.Id,
u.DisplayName,
p.Id,
p.AcceptedAnswerId
HAVING SUM(p.Score) > 1
)
SELECT
a.UserId,
a.DisplayName,
a.PostId,
a.AcceptedAnswerId,
a.TotalScore,
q.UserId,
q.DisplayName,
q.PostId,
q.AcceptedAnswerId,
q.TotalScore
FROM spool_me AS a
JOIN spool_me AS q
ON a.PostId = q.AcceptedAnswerId
ORDER BY a.TotalScore DESC;
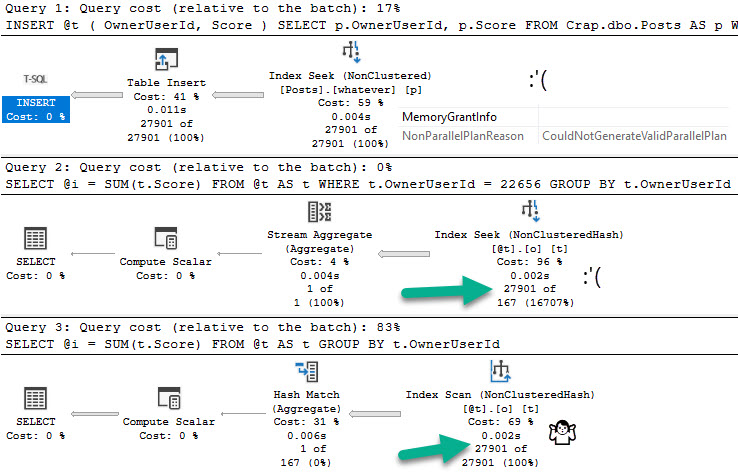
Wowee. We really done did it. But now what does the query plan look like?
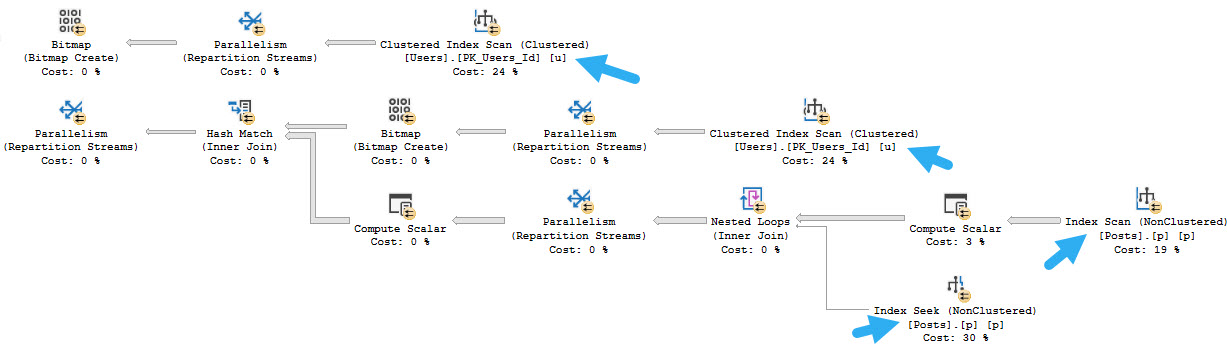
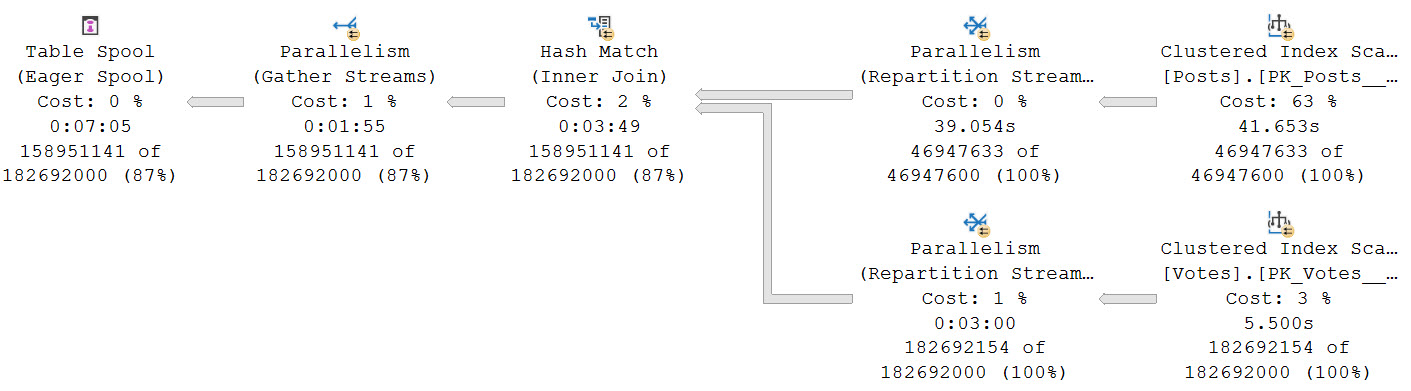
There are now two accesses of Posts and two accesses of Users, and three joins (one Hash Join isn’t in the screen cap).
Detection
Obviously, the optimizer knows it has to build a query plan that reflects the CTE being joined.
Since it’s smart enough to do that, it should be smart enough to use a Spool to cache things and prevent the additional accesses.
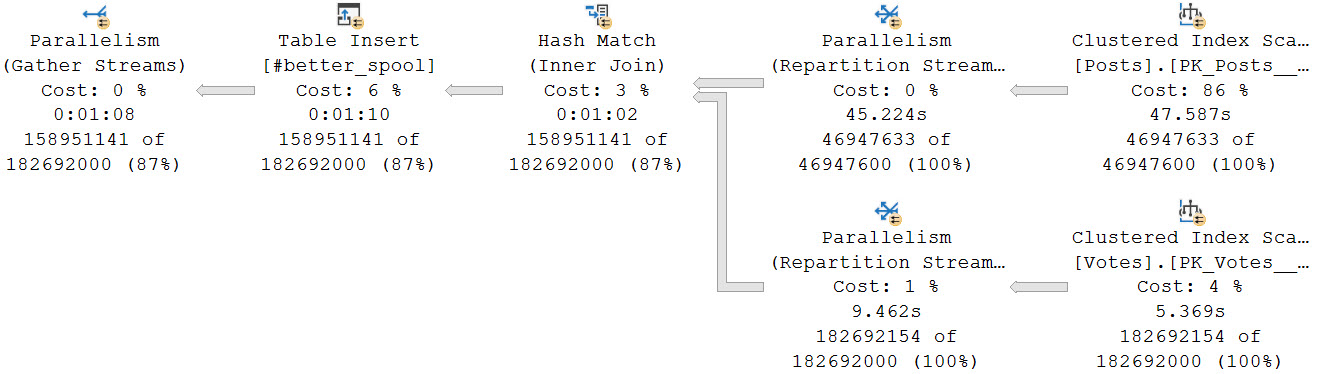
Comparatively, using a #temp table to simulate a Spool, is about twice as fast. Here’s the CTE plan:
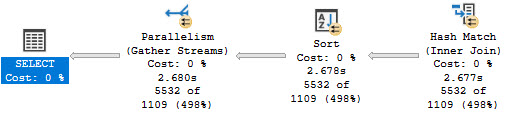
Here’s the Spool Simulator Plan™
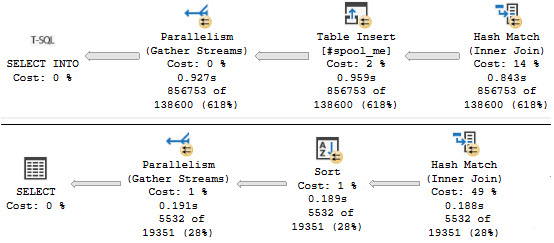
Given the optimizer’s penchant for spools, this would be another chance for it to shine on like the crazy diamond it is.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.