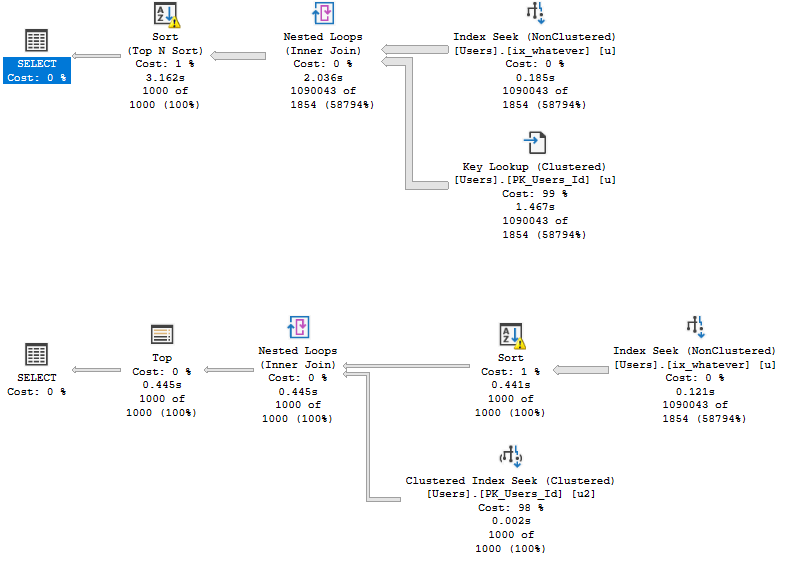
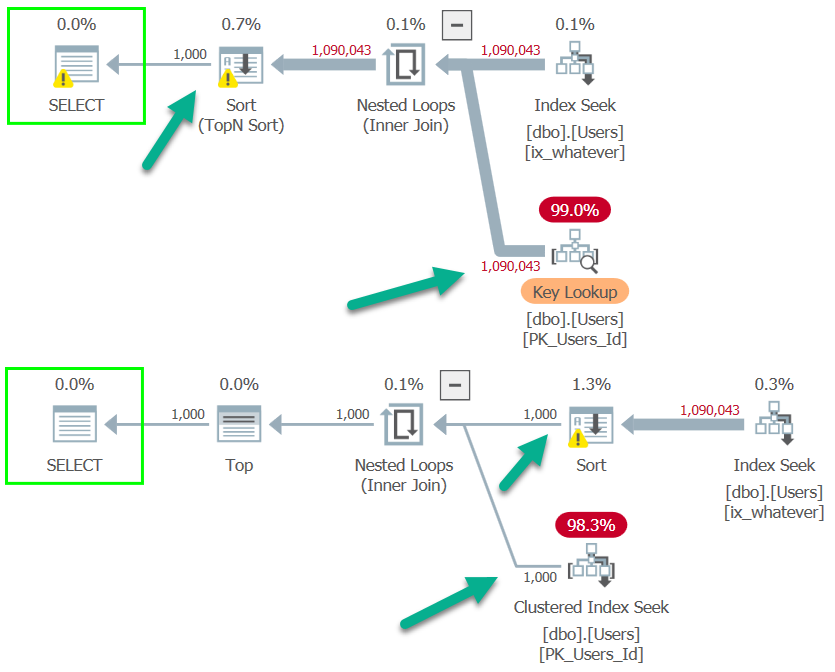
Nope.
The sad news for you here is that nothing aside from selecting a CTE into a real or temporary table will materialize the result of the query within in it.
WITH
cte AS
(
SELECT TOP (1)
u.Id
FROM dbo.Users AS u
)
SELECT
c1.*
FROM cte AS c1
JOIN cte AS c2
ON c1.Id = c2.Id
JOIN cte AS c3
ON c1.Id = c3.Id;
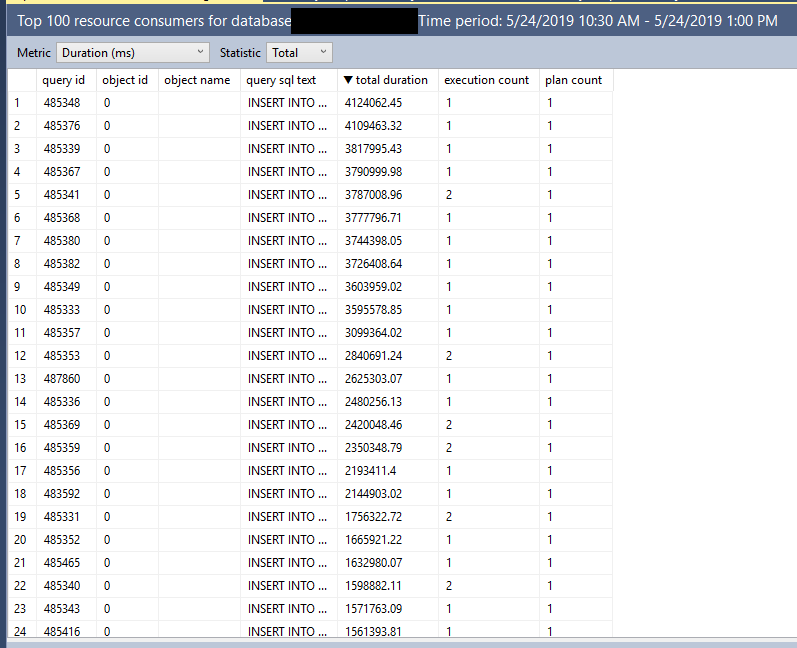
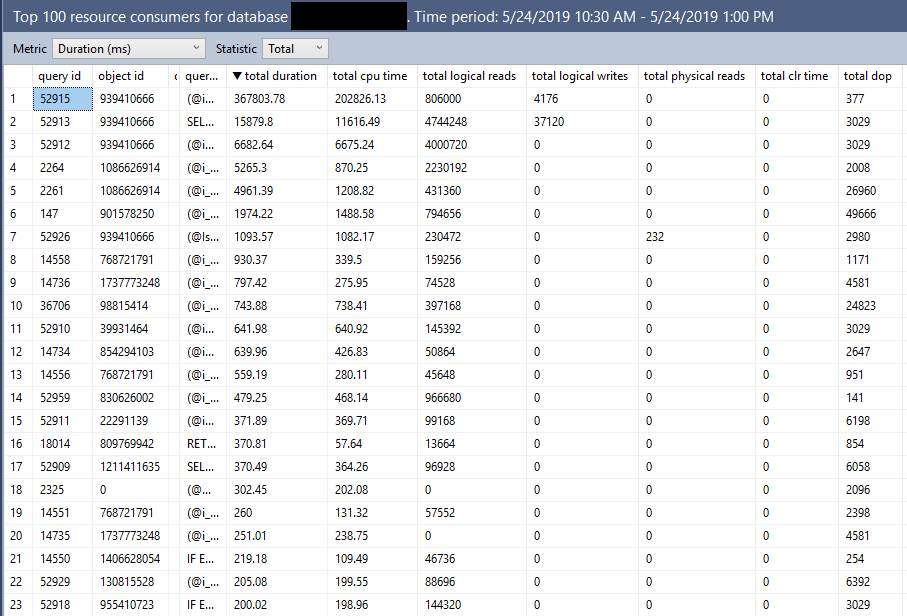
This query will still have to touch the Users table three times. I’ve blogged about this part before, of course.
Bounce
You may notice something interesting in there, though, once you get past the disappointment of seeing three scans of the Users table.
Each scan is preceded by the TOP operator. This can sometimes be where people confuse the behavior of TOP in a Common Table Expression or Derived Table.
It’s not a physical manifestation of the data into an object, but (at least for now) it is a logical separation of the query semantics.
In short, it’s a fence.
The reason why it’s a fence is because using TOP sets a row goal, and the optimizer has to try to meet (but not exceed) that row goal for whatever part of the query is underneath it.
Strange
Take this query for example, which loads a bunch of work into a Common Table Expression with a TOP in it:
WITH
Posts AS
(
SELECT TOP (1000)
p.*
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.Score > 500
AND EXISTS
(
SELECT
1/0
FROM dbo.Users AS u
WHERE u.Id = p.OwnerUserId
)
AND EXISTS
(
SELECT
1/0
FROM dbo.Badges AS b
WHERE b.UserId = p.OwnerUserId
)
ORDER BY p.Score DESC
)
SELECT
u.DisplayName,
p.PostTypeId,
p.Score
FROM dbo.Users AS u
JOIN Posts AS p
ON p.OwnerUserId = u.Id
ORDER BY u.Reputation DESC;
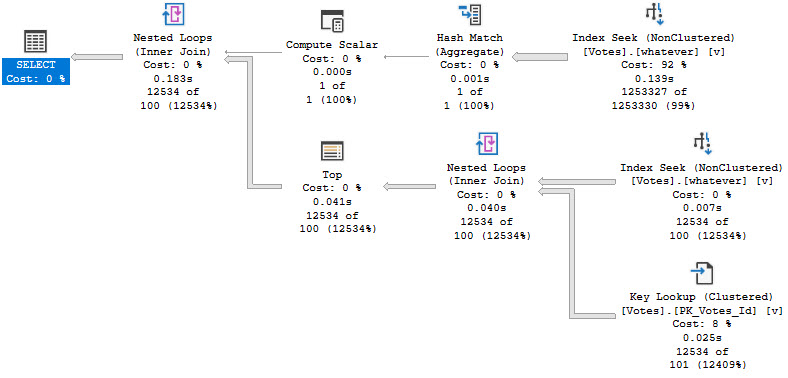
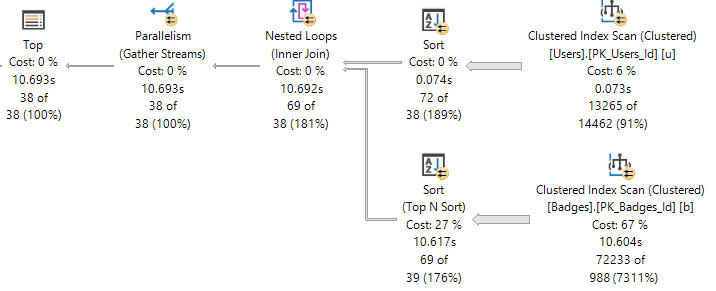
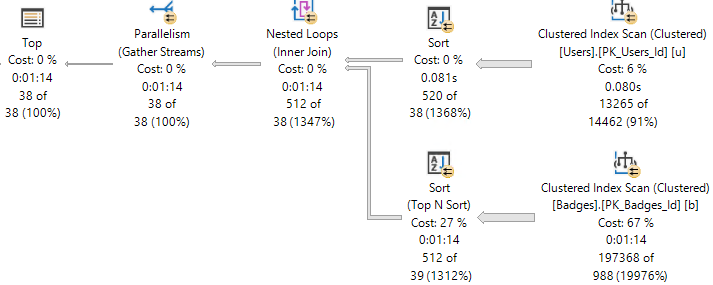
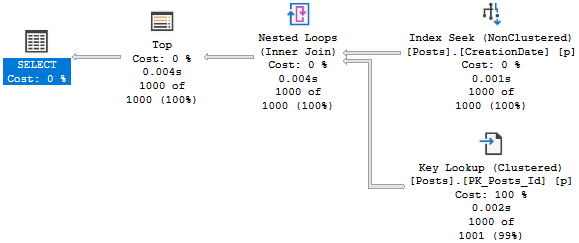
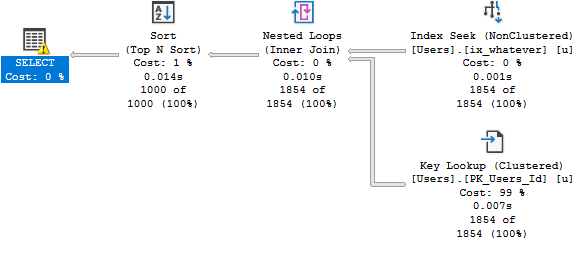
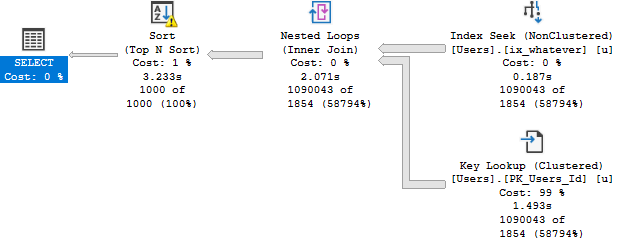
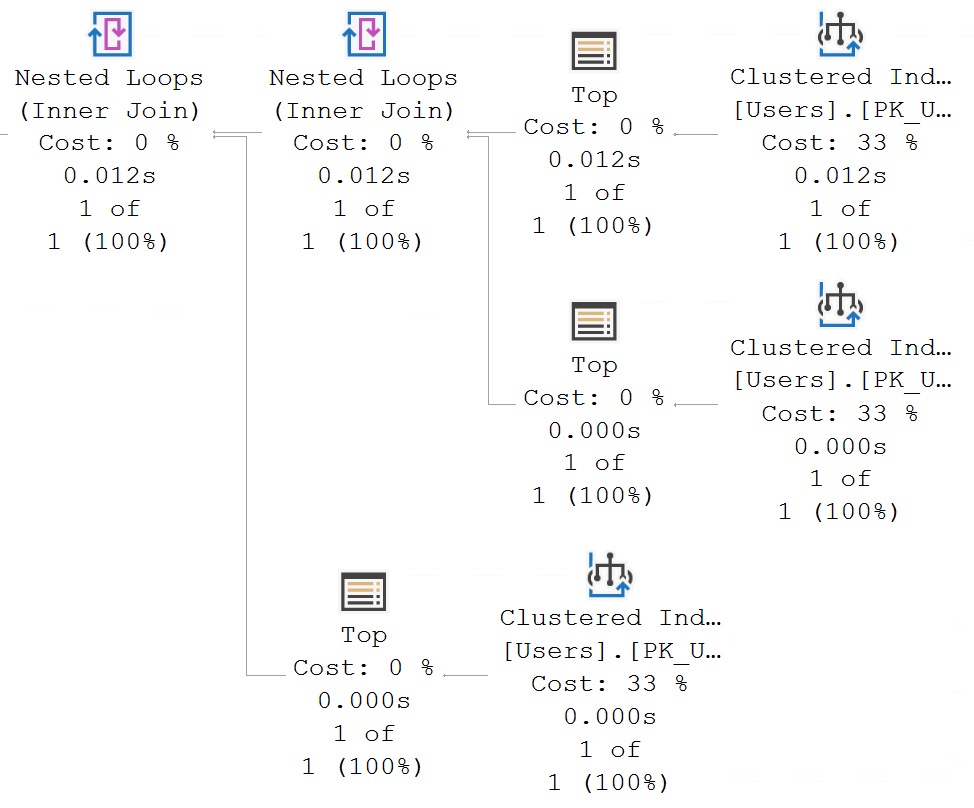
And the plan for it looks like this:

All the work within the Common Table Expression is fenced by the top.
There are many times you can use this to your advantage, when you know certain joins or predicates can produce a very selective result.
Care Control
As a final note, just be really careful how you position your TOPs. They insert loads of semantic differences to the query.
If you don’t believe me, put a TOP in the wrong place and watch your results change dramatically.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.