Introductions
There are many ways to express queries in SQL. How different rewrites perform will largely be a function of:
- You not doing anything ridiculous
- Queries having good indexes in place
- The optimizer not seeing through your tricks and giving you the same query plan
The first rule of rewrites is that they have to produce the same results, of course. Logical equivalency is tough.
In today and tomorrow’s posts I’m going to compare a couple different scenarios to get the top value.
There are additional ways to rewrite queries like this, of course, but I’m going to show you the most common anti-pattern I see, and the most common solution that tends to work better.
Right And Proper Indexing
For today’s post, we’re going to use this index:
CREATE INDEX p ON dbo.Posts(OwnerUserId, Score DESC) INCLUDE(PostTypeId) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Which is going to give this query proper support. Sure, we could also add an index to the Users table, but the one scan is trivially fast, and probably not worth it here.
SELECT
u.DisplayName,
u.Reputation,
p.PostTypeId,
p.Score
FROM dbo.Users AS u
JOIN
(
SELECT
p.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
) AS p
ON p.OwnerUserId = u.Id
AND p.n = 1
WHERE u.Reputation > 50000
ORDER BY
u.Reputation DESC,
p.Score DESC;
The general idea is to find all users with a reputation over 50,000, along with their highest scoring post.
I know, you’re looking at this and thinking “jeez Erik, why are you selecting * here? don’t you know how bad and dumb you are for that?”
Well, SQL Server is smart enough to ignore that and only deal with the columns in the outer select.
The Query Plan
If you create the index and run this, the query plan looks something like this:
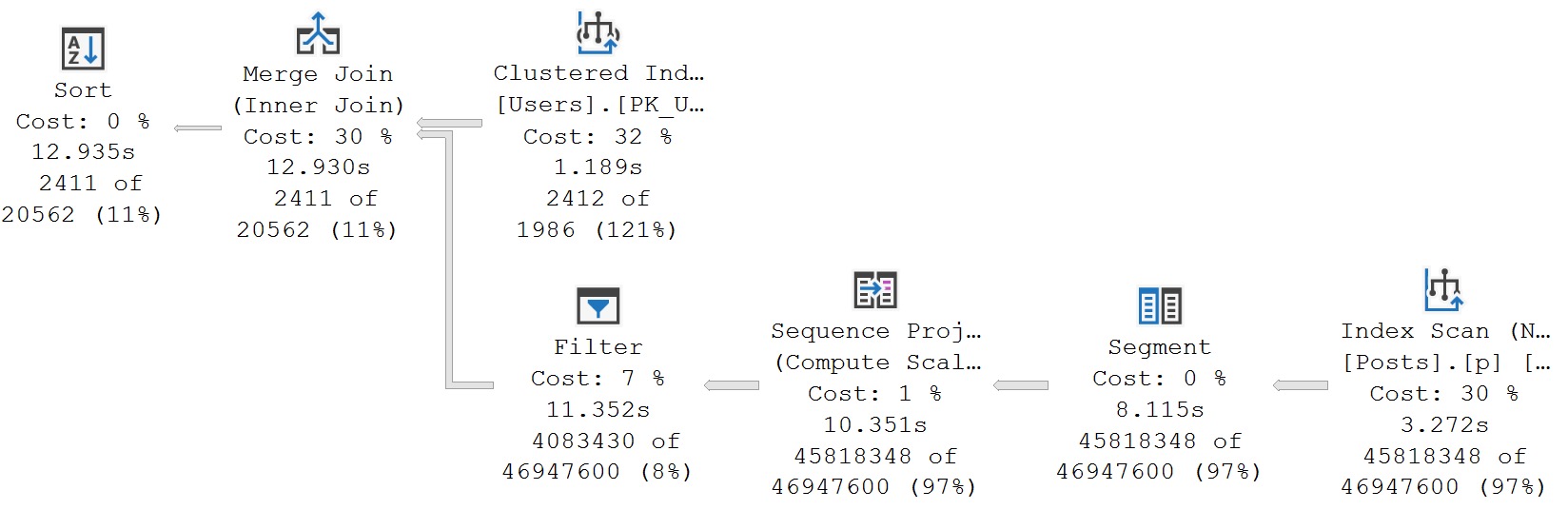
The majority of the time spent in this plan is the ~11 seconds between the scan of the Posts table and the Filter operator.
The filter is there to remove rows where the result of the ROW_NUMBER function are greater than 1.
I guess you could say less than 1, too, but ROW_NUMBER won’t produce rows with 0 or negative numbers naturally. You have to make that happen by subtracting.
A Better Query Pattern?
Since only ~2400 rows are leaving the Users table, and we have a good index on the Posts table, we want to take advantage of it.
Rather than scan the entire Posts table, generate the ROW_NUMBER, apply the filter, then do the join, we can use CROSS APPLY to push things down to where we touch the Posts table.
SELECT
u.DisplayName,
u.Reputation,
p.PostTypeId,
p.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
ORDER BY p.Score DESC
) AS p
WHERE u.Reputation > 50000
ORDER BY
u.Reputation DESC,
p.Score DESC;
This is logically equivalent, but it blows the other query out of the water, performance-wise.
A Better Query Plan?
Here’s the query plan for the cross apply query:
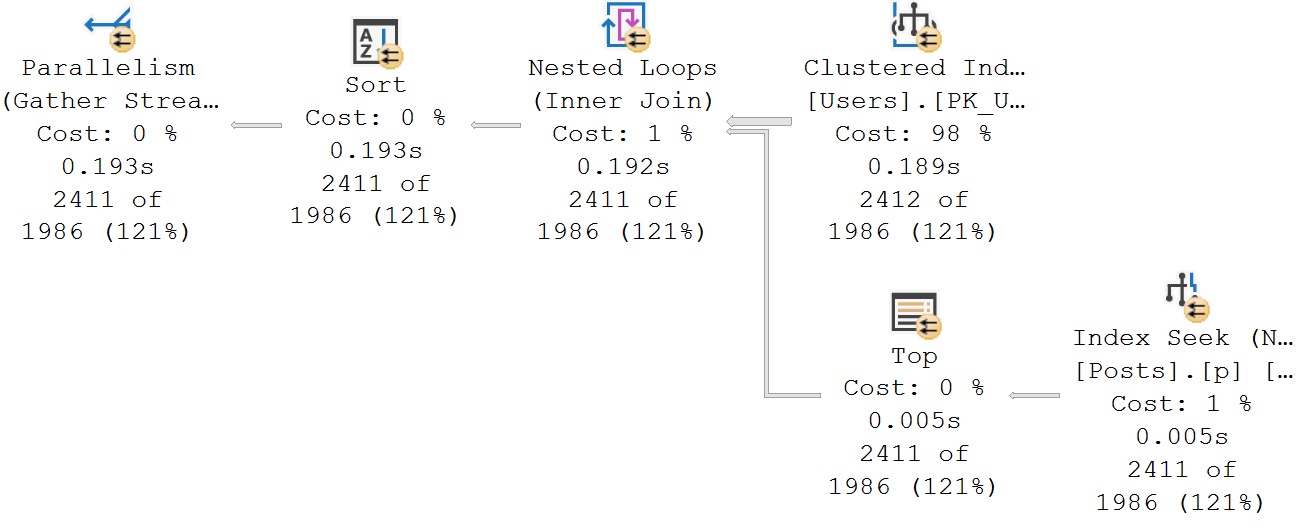
Why Is This better?
In this case, having a good index to use, and a small outer result from the Users table, the cross apply query is way better.
This is also due to the Id column of Users being the Primary Key of the table. For this sort of one to many join, it works beautifully. If it were a many to many scenario, it could be a toss up, or ROW_NUMBER could blow it out of the water.
The way this type of Nested Loops Join works (Apply Nested Loops), is to take each row from the outer input (Users table) and seek to it in the Posts table.
Without that good index up here, this would likely be a disaster with an Eager Index Spool in the plan. We definitely don’t want that, here.
But you know, there are many different types of posts. We might want to know someone’s high score for questions, answers, and more.
In tomorrow’s post, we’ll look at how to do that, and performance tune the query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Getting The Top Value Per Group With Multiple Conditions In SQL Server: Row Number vs. Cross Apply With MAX
- Multiple Distinct Aggregates: Still Harm Performance Without Batch Mode In SQL Server
- Residual Predicates In SQL Server Query Plans
- SQL Server 2017 CU 30: The Real Story With SelOnSeqPrj Fixes