Fixing Parallel Row Skew With TOP In SQL Server (With A Brief Re-Complaint About CXCONSUMER Waits)
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
A Little About SOS_SCHEDULER_YIELD Waits In SQL Server
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Views get a somewhat bad rap from performance tuners, but… It’s not because views are inherently bad. It’s just that we’ve seen things. Horrible things.
Attack ships on fire off the shoulder of Orion… I watched sea-beams glitter in the dark near the Tannhäuser Gate. All those moments will be lost in time, like tears in rain…
The problem is really the stuff that people stick into views. They’re sort of like a junk drawer for data. Someone builds a view that returns a correct set of results, which becomes a source of truth. Then someone else comes along and uses that view in another view, because they know it returns the correct results, and so on and so on. Worse, views tend to do a bunch of data massaging, left joining and coalescing and substringing and replacing and case expressioning and converting things to other things. The bottom line is that views are as bad as you make them.
The end result is a trash monster with a query plan that can only be viewed in full from deep space.
When critical processes start to rely on these views, things inevitably slow to a crawl.
I’ve said all that about views to say that the exact same problem can happen with inline table valued functions. I worked with a client last year who (smartly) started getting away from scalar and multi-statement functions, but the end results were many, many layers of nested inline functions.
Performance wasn’t great. It wasn’t worse, but it was nothing to gloat and beam over.
The Case For Views
Really, the main reason to use a view over an inline table valued function is the potential for turning it into an indexed view. If Microsoft would put an ounce of effort into making indexed views more useful and usable, it would loom a bit larger.
There are some niche reasons too, like some query generation applications use metadata discovery to build dynamic queries that can’t “see” into inline table valued functions the way they can with views, but I try not to get bogged down in tool-specific requirements like that without good reason.
Both views and inline table valued functions offer schemabinding as a creation option. This, among other incantations, are necessary if you’re going to follow the indexed view path.
But, here we find ourselves at the end of the case for views. Perhaps I’m not digging deep enough, but I can’t find much realistic upside.
While doing some research for this, I read through the CREATE VIEW documentation to see if I was missing anything. I was a bit surprised by this, but don’t see it as a great reason to use them:
CHECK OPTION
Forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
If you’re into that sort of thing, perhaps this will make views more appealing to you. I’m not sure I can think of why I’d want this to happen, but 🤷♂️
The Case For Inline Functions
Now that we’re squared away on views, and we’ve made sure we’re starting with the understanding that either of these module types can be lousy for performance if you put a lousy query in them, and fail to create useful indexes for those queries to access data efficiently.
What would sway my heart of stone towards the humble inline table valued function?
Parameters.
Views can’t be created in a way to pass parameter directly to them. This can be a huge performance win under the right conditions, especially because if you use cross or outer apply to integrate an inline table valued function into your query. You can pass table columns directly in to the function as parameter values. Inline table valued functions take the ick away.
You know how with stored procedures, if you want to use one to process multiple rows from a table, the most workable approach is to use a loop or cursor to assign row values to parameters, and then execute the procedure with them?
Just an example, if you had a stored procedure to take (to make it simple, full) backups, it would be handy to be able to do something like this:
EXEC dbo.TakeAFullBackup
@DatabaseName AS
SELECT
d.name
FROM sys.databases AS d
WHERE d.database_id > 4;
But no, we have to write procedural code to get a list of database names, loop through them, and execute the procedure for each one (or some other close-enough approximation).
Kinda lame, SQL Server. Kinda lame.
Rat Race
When I first came across this oddity, I probably thought (and wrote) things like: “though this is a rare occurrence in views…”
Time has tried that line of thinking and found it wanting. I’ve seen this happen many, many times over now. It’s funny, the more things you learn that can go wrong in a query plan, the more things you become quite paranoid about. The mental checklist is astounding.
Let’s start, as we often do, with an index:
CREATE INDEX
p
ON dbo.Posts
(OwnerUserId, Score DESC)
INCLUDE
(CreationDate, LastActivityDate)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Now, before we move on, it’s worth noting that this issue is fixed under certain conditions:
I’m not sure which CU this fix was released for in SQL Server 2019, it’s not in any that I can find easily
You’re on SQL Server 2022 and using compatibility level 160
From my testing, it doesn’t matter which compatibility level you’re in on SQL Server 2017 or 2019, as long as optimizer hot fixes are enabled.
/*Using a database scoped configuration*/
ALTER DATABASE SCOPED CONFIGURATION
SET QUERY_OPTIMIZER_HOTFIXES = ON;
/*Using a trace flag instead*/
DBCC TRACEON(4199, -1);
/*SQL Server 2022+ only*/
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 160;
For our purposes, we’ll be using SQL Server 2022 in compatibility level 150, with query optimizer hot fixes disabled.
No Problemo (Query)
Here’s a view and a query, where things work just fine:
CREATE OR ALTER VIEW
dbo.DasView
WITH SCHEMABINDING
AS
SELECT
p.Score,
p.OwnerUserId,
p.CreationDate,
p.LastActivityDate,
DENSE_RANK() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
) AS PostRank
FROM dbo.Posts AS p;
GO
SELECT
p.*
FROM dbo.DasView AS p
WHERE p.OwnerUserId = 22656;
GO
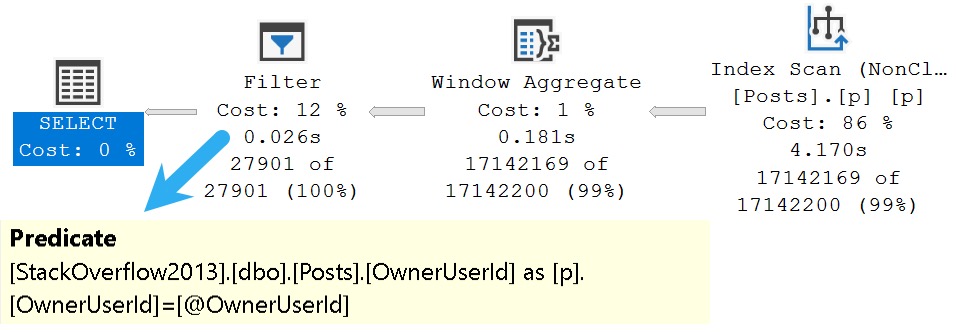
The reason this works fine is because the where clause contains a literal value, and not a variable or parameter placeholder.
iron seek
Everything is how we would expect this query plan to look, given the indexes available.
Si Problemo (View)
Where things become wantonly unhinged is when we supply a placeholder for that literal value.
CREATE OR ALTER PROCEDURE
dbo.DasProcedure
(
@OwnerUserId integer
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
SELECT
p.*
FROM dbo.DasView AS p
WHERE p.OwnerUserId = @OwnerUserId
/*OPTION(QUERYTRACEON 4199)*/
/*OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_160'))*/;
END;
GO
EXEC dbo.DasProcedure
@OwnerUserId = 22656;
GO
Note that I have a query trace on and use hint here, but quoted out. You could also use these to fix the issue for a single query, but my goal is to show you what happens when things aren’t fixed.
Here’s what that looks like:
asbestos
Rather than a seek into the index we created, the entire thing is scanned, and we have a filter that evaluates our placeholder from 17 million rows and whittles the results down to 27,901 rows.
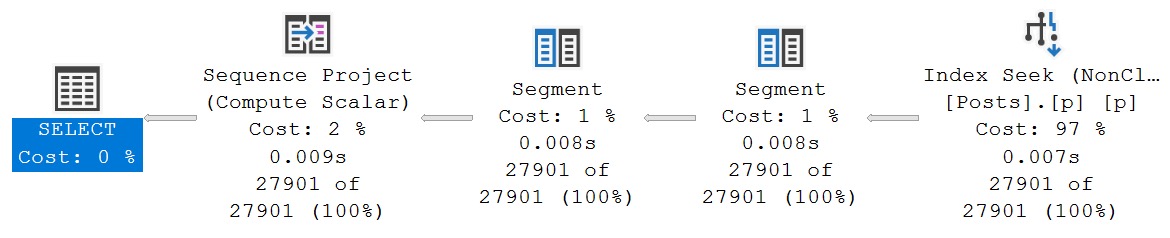
No Problemo (Function)
Using an inline table valued function allows us to bypass the issue, without any hints or database settings changes.
CREATE OR ALTER FUNCTION
dbo.DasFunction
(
@OwnerUserId integer
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT
p.Score,
p.OwnerUserId,
p.CreationDate,
p.LastActivityDate,
DENSE_RANK() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
) AS PostRank
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @OwnerUserId;
GO
This changes our procedure as well:
CREATE OR ALTER PROCEDURE
dbo.DasProcedure
(
@OwnerUserId integer
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
SELECT
p.*
FROM dbo.DasFunction(@OwnerUserId) AS p;
END;
GO
EXEC dbo.DasProcedure
@OwnerUserId = 22656;
And our query plan goes back to normal.
fastigans
Even if you don’t have this specific problem, it’s often worth exploring converting views to inline table valued functions, because quite often there is a common filtering or joining criteria, and having parameters to express that is beneficial in a couple ways:
It better shows the intent of module and what it can be used for
It prevents developers from forgetting filtering criteria and exploding results
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Common table expressions remind me of clothes in the 70s. A bunch of people with no taste convinced a bunch of people with no clue that they should dress like them, and so we got… Well, at least we got the 80s afterwards.
The big draw with common table expressions is that they filled in some blanks that derived tables left unanswered.
The first problem with common table expressions is that most people use them like nose and ear hair trimmers: they just sort of stick them in and wave them around until they’re happy, with very little observable feedback as to what has been accomplished.
The second big problem with common table expressions is that the very blanks they were designed to fill in are also the very big drawbacks they cause, performance-wise. Sort of like a grand mal petard hoisting.
To bring things full circle, asking someone why they used a common table expression is a lot like asking someone why they wore crocheted bell bottoms with a velour neckerchief in the 70s. Someone said it was a good idea, and… Well, at least we got the 80s afterwards.
Much like joins and Venn diagrams, anyone who thinks they have some advanced hoodoo to teach you about common table expressions is a charlatan or a simpleton. They are one of the least advanced constructs in T-SQL, and are no better or worse than any other abstraction layer, with the minor exception that common table expressions can be used to build recursive queries.
Other platforms, enviably, have done a bit to protect developers from themselves, by offering ways to materialize common table expressions. Here’s how Postgres does it, which is pretty much the opposite of how SQL Server does it.
By default, and when considered safe, common table expressions are materialized to prevent re-execution of the query inside them.
You can force the issue by doing this (both examples are from the linked docs):
WITH w AS MATERIALIZED (
SELECT * FROM big_table
)
SELECT * FROM w AS w1 JOIN w AS w2 ON w1.key = w2.ref
WHERE w2.key = 123;
Or go your own way and choose to not materialize it:
WITH w AS NOT MATERIALIZED (
SELECT * FROM big_table
)
SELECT * FROM w AS w1 JOIN w AS w2 ON w1.key = w2.ref
WHERE w2.key = 123;
You don’t get those options in SQL Server as of this writing, which really sucks because developers using other platforms may have certain expectations that are, unfortunately, not met.
Likewise, other sane and rational platforms use MVCC (optimistic locking) by default, which SQL Server does not. Another expectation that will unfortunately not be met for cross-platform developers.
Common Table Cult
The amount of developer-defense that common table expressions get is on par with the amount of developer-defense that table variables get.
It’s quite astounding to witness. How these things became such sacred cows is beyond me.
First, there are times when using a common table expression has no impact on anything:
WITH
nocare AS
(
SELECT
u.*
FROM dbo.Users AS u
WHERE u.Reputation > 999999
)
SELECT
n.*
FROM nocare AS n;
WITH
nocare AS
(
SELECT
u.*
FROM dbo.Users AS u
)
SELECT
*
FROM nocare AS n
WHERE n.Reputation > 999999;
SQL Server is at least smart enough to be able to push most predicates used outside of common table expressions up into the common table expression.
One example of such a limitation is when you put a windowing function into a common table expression:
WITH
nocare AS
(
SELECT
v.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
v.UserId
ORDER BY
v.CreationDate
)
FROM dbo.Votes AS v
)
SELECT
n.*
FROM nocare AS n
WHERE n.VoteTypeId = 8
AND n.n = 0;
If VoteTypeId were in the PARTITION BY clause of the windowing function, it could be pushed into the common table expression portion of the query. Without it in there, it has to be filtered out later, when the where clause also looks for rows numbered as 0.
But this does bring us to a case where common table expressions are generally okay, but would perform equivalently with a derived table: when you need to stack some logic that can’t be performed in a single pass.
Using a common table expression to filter out the results of a windowing function just can’t be done without some inner/outer context. Since objects in the select list are closer than they appear, you can’t reference them in the where clause directly.
I’m fine with that, as shown in the example above.
Common Stacks
Stacked common table expressions are also “fine” up to a point, and with caveats.
DECLARE
@page_number int = 1,
@page_size int = 100;
WITH
f /*etch*/ AS
(
SELECT TOP (@page_number * @page_size)
p.Id,
n =
ROW_NUMBER() OVER
(
ORDER BY
p.Id
)
FROM dbo.Posts AS p
ORDER BY
p.Id
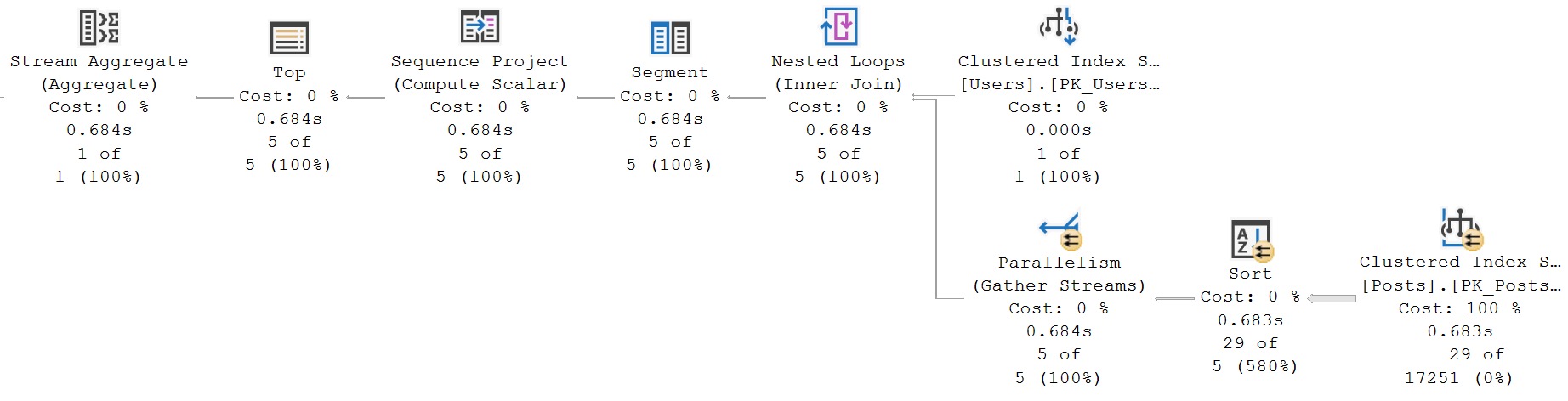
),
o /*ffset*/ AS
(
SELECT TOP (@page_size)
f.id
FROM f
WHERE f.n >= ((@page_number - 1) * @page_size)
ORDER BY
f.id
)
SELECT
p.*
FROM o
JOIN dbo.Posts AS p
ON o.id = p.Id
ORDER BY
p.Id;
The reason why this is okay is because each common table expression has a single reference. There are two points in the query plan where data is acquired from the Posts table.
uno dos!
Where things get tricky is when you keep doing it over and over again.
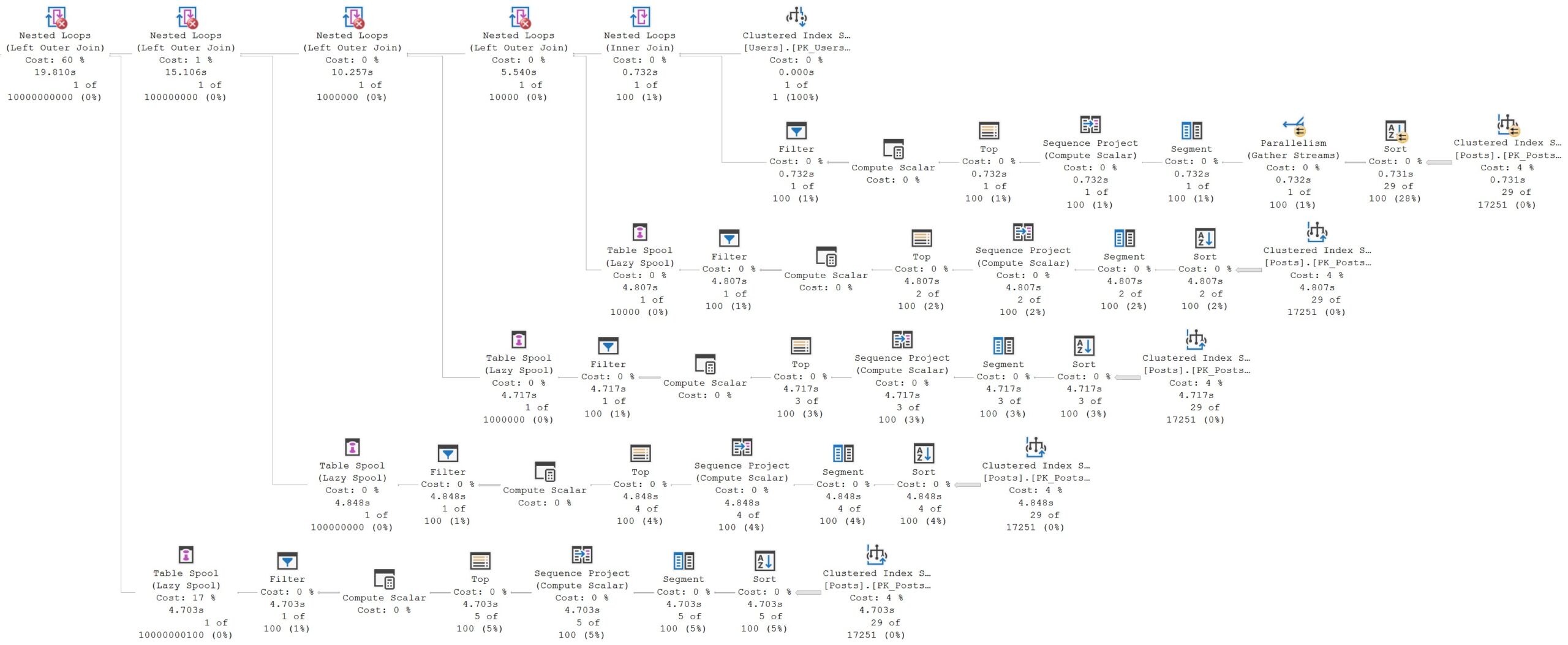
Attack Stacks
Take a query like this, and imagine what the query plan will look like for a moment.
WITH
top5 AS
(
SELECT
p.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.PostTypeId = 1
)
SELECT
u.DisplayName,
t1.Title,
t2.Title,
t3.Title,
t4.Title,
t5.Title
FROM dbo.Users AS u
LEFT JOIN top5 AS t1
ON t1.OwnerUserId = u.Id
AND t1.n = 1
LEFT JOIN top5 AS t2
ON t2.OwnerUserId = u.Id
AND t2.n = 2
LEFT JOIN top5 AS t3
ON t3.OwnerUserId = u.Id
AND t3.n = 3
LEFT JOIN top5 AS t4
ON t4.OwnerUserId = u.Id
AND t4.n = 4
LEFT JOIN top5 AS t5
ON t5.OwnerUserId = u.Id
AND t5.n = 5
WHERE t1.OwnerUserId IS NOT NULL;
An utter disaster, predictably:
moo 🐮
We hit the Posts table a total of five times, or once for each reference back to the original common table expression.
This is not a good use of a common table expression, and is a pattern in general to avoid when using them.
Think of common table expressions sort of like ordering a Rum Martinez. You might be happy when the results eventually show up, but every time you say “Rum Martinez”, the bartender has to go through the whole process again.
There’s no magickal pitcher of Rum Martinez sitting around for your poor bartender to reuse.
That’s called a Shirley Temp Table.
Pivot Peeve
This particular query could use a temp table to materialize the five rows, and re-joining to that would be cheap and easy, even five times, since it’s only five rows going in.
WITH
top5 AS
(
SELECT
p.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.PostTypeId = 1
)
SELECT
t.OwnerUserId,
t.Title,
n
INTO #top5
FROM top5 AS t
WHERE t.n <= 5;
You could also also just PIVOT this one, too:
WITH
u AS
(
SELECT TOP (5)
u.DisplayName,
p.Title,
n = ROW_NUMBER() OVER (ORDER BY p.Score DESC)
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.OwnerUserId = 22656
AND p.PostTypeId = 1
ORDER BY
p.Score DESC
)
SELECT
p.*
FROM u AS u
PIVOT
(
MAX(Title)
FOR n IN ([1], [2], [3], [4], [5])
) AS p;
For all the problems PIVOT can cause when misused, this is a full 19 seconds faster than our most precious common table expression query.
With a half-decent index, it’d probably finish in just about no time.
PIVOT TIME!
I’d take this instead any day.
A Note On Recursion
There may be times when you need to build a recursive expression, but you only need the top N children, or you want to get rid of duplicates in child results.
Since you can’t use DISTINCT, TOP, or OFFSET/FETCH directly in a recursive common table expression, some nesting is required.
Of course, we can’t currently nest common table expressions, and to be clear, I think that idea is dumb and ugly.
If Microsoft gives us nested common table expressions before materialized common table expressions, I’ll never forgive them.
WITH
postparent AS
(
SELECT
p.Id,
p.ParentId,
p.OwnerUserId,
p.Score,
p.PostTypeId,
Depth = 0,
FullPath = CONVERT(varchar, p.Id)
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20131229'
AND p.PostTypeId = 1
UNION ALL
SELECT
p2.Id,
p2.ParentId,
p2.OwnerUserId,
p2.Score,
p2.PostTypeId,
p2.Depth,
p2.FullPath
FROM
(
SELECT
p2.Id,
p2.ParentId,
p2.OwnerUserId,
p2.Score,
p2.PostTypeId,
Depth = pp.Depth + 1,
FullPath = CONVERT(VARCHAR, CONCAT(pp.FullPath, '/', p2.Id)),
n = ROW_NUMBER() OVER (ORDER BY p2.Score DESC)
FROM postparent pp
JOIN dbo.Posts AS p2
ON pp.Id = p2.ParentId
AND p2.PostTypeId = 2
) AS p2
WHERE p2.n = 1
)
SELECT
pp.Id,
pp.ParentId,
pp.OwnerUserId,
pp.Score,
pp.PostTypeId,
pp.Depth,
pp.FullPath
FROM postparent AS pp
ORDER BY
pp.Depth
OPTION(MAXRECURSION 0);
To accomplish this, you need to use a derived table, filtering the ROW_NUMBER function outside of it.
This is a more common need than most developers realize when working with recursive common table expressions, and can avoid many performance issues and max recursion errors.
It’s also a good way to show off to your friends at disco new wave parties.
Common Table Ending
Common table expressions can be handy to add some nesting to your query so you can reference generated expressions in the select list as filtering elements in the where clause.
They can even be good in other relatively simple cases, but remember: SQL Server does not materialize results, though it should give you the option to, and the optimizer should have some rules to do it automatically when a common table expression is summoned multiple times, and when it would be safe to do so. I frequently pull common table expression results into a temp table, both to avoid the problems with re-referencing them, and to separate out complexity. The lack of materialization can be hell on cardinality estimation.
In complicated queries, they can often do more harm than good. Excuses around “readability” can be safely discarded. What is “readable” to you, dear human, may not be terribly understandable to the optimizer. You’re not giving it any better information by using common table expressions, nor are you adding any sort of optimization fence to any queries in them without the use of TOP or OFFSET/FETCH. Row goals are a hell of a drug.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I’ll be brief here, and let you know exactly when I’ll use IN and NOT IN rather than anything else:
When I have a list of literal values
That’s it. That’s all. If I have to go looking in another table for anything, I use either EXISTS or NOT EXISTS. The syntax just feels better to me, and I don’t have to worry about getting stupid errors about subqueries returning more than one value.
For IN clauses, it’s far less of an ordeal, usually. But for NOT IN, there are some additional concerns around NULLable columns.
Of course, actual NULL values really screw things up, but even when SQL Server needs to protect itself against potential NULL values, you can end up in performance hospice.
Historical
First, a little bit of history. With NOT IN. Take the below script, and flip the insert into the @bad table variable to use 2 instead of NULL, after you’ve seen what happens with NULL.
DECLARE
@good table
(
id int NOT NULL
);
DECLARE
@bad table
(
id int NULL
);
INSERT
@good
(
id
)
VALUES
(1);
INSERT
@bad
(
id
)
VALUES
(NULL); /*Change this between NULL and 2*/
SELECT
records =
COUNT_BIG(*) /*Should be 1, or something*/
FROM @good AS g
WHERE g.id NOT IN
(
SELECT
b.id
FROM @bad AS b
);
You’ll see pretty quickly that NOT IN gives you wonky results when it hits a NULL.
This is known.
Imaginary NULLs
Let’s take the below setup. Though each table allows NULLs in their single column, no NULL values will be inserted into them.
CREATE TABLE
#OldUsers
(
UserId int NULL
);
CREATE TABLE
#NewUsers
(
UserId int NULL
);
/*
But neither one will have any NULL values at all!
*/
INSERT
#OldUsers WITH (TABLOCK)
(
UserId
)
SELECT
p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL;
INSERT
#NewUsers WITH (TABLOCK)
(
UserId
)
SELECT
c.UserId
FROM dbo.Comments AS c
WHERE c.UserId IS NOT NULL;
The real lesson here is that if you know that no NULL values are allowed into your tables, you should specify the columns as NOT NULL.
I know, it’s scary. Really scary. Errors. What if. How dare.
But these are the kind of adult decisions you’ll have to make as an application developer.
Be brave.
Protect Your NULL
The big problem with NOT IN, is that SQL Server goes into defensive driving mode when you use it under NULLable conditions.
I don’t have a license because it would be irresponsible, and I’ve lived my entire life in big cities where having a car would be more trouble than it’s worth. But I assume that when I see people complain about drivers not knowing what to do the second there’s a rain drizzle or a snow flurry somewhere in the area is a similarly annoying scenario out there on the roads. All of a sudden, seemingly competent drivers turn into complete basket cases and drive like they’ve got a trunk full of dead bodies clowns.
Here’s an example of a bad way to deal with the situation, vs. a good way to deal with the situation:
/*Bad Way*/
SELECT
records = COUNT_BIG(*)
FROM #NewUsers AS nu
WHERE nu.UserId NOT IN
(
SELECT
ou.UserId
FROM #OldUsers AS ou
);
/*Good Way*/
SELECT
records =
COUNT_BIG(*)
FROM #NewUsers AS nu
WHERE NOT EXISTS
(
SELECT
1/0
FROM #OldUsers AS ou
WHERE nu.UserId = ou.UserId
);
Note the very professional formatting and correct syntax. Ahem. Bask.
Count to 10 while you’re basking.
Results
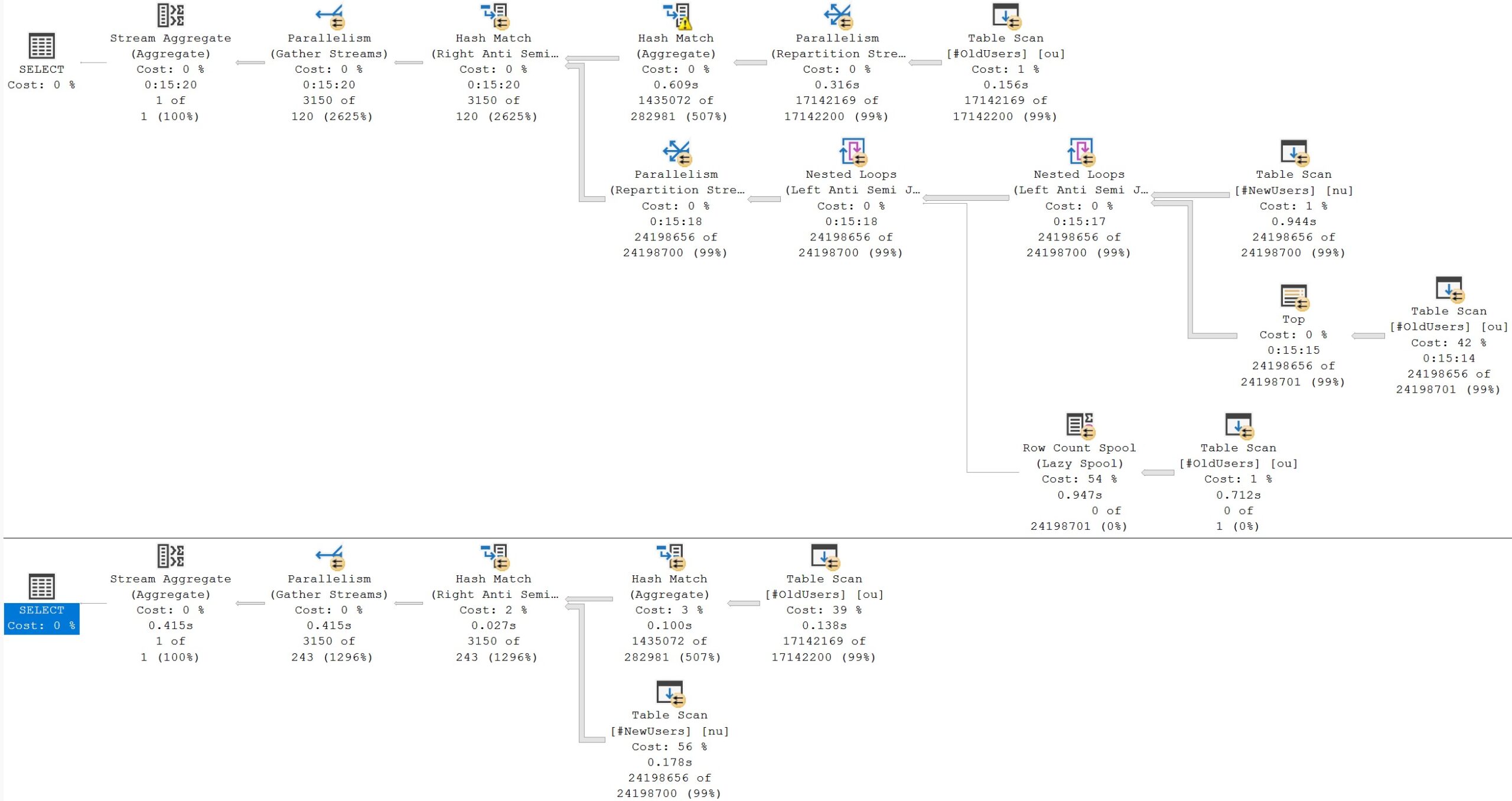
The resulting execution plan for each example should be illuminating. Here they are:
enabled buttons
The NOT IN version takes 15 minutes, and the NOT EXISTS version takes 415ms.
Reality Bites
Since there are no NULLs, the first query returns the correct results. But the amount of work SQL Server has to do to make sure there are no NULLs is both absurd and preposterous.
If you’re like me, and you want to throw the query optimizer in the garbage every time you see a TOP over a Scan, you might say something like “an index would make this really fast”.
You wouldn’t be wrong, but most people either:
Take bad advice and never index #temp tables
Create nonclustered indexes on #temp tables that don’t get used
Well, you get what you deserve pay for.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I end up converting a lot of derived joins, particularly those that use windowing functions, to use the apply syntax. Sometimes good indexes are in place to support that, other times they need to be created to avoid an Eager Index Spool.
One of the most common questions I get is when developers should consider using apply over other join syntax.
The short answer is that I start mentally picturing the apply syntax being useful when:
There’s a small outer table (FROM), and a large inner table (APPLY)
I need to do a significant amount of work on the inner side of a join
The goal of the query is top N per group, or something similar
I’m trying to get parallel nested loops instead of some alternative plan choice
To replace a scalar UDF in the select list with an inline UDF
In order to use the VALUES construct in an odd way
Most of this is situational, and requires a bit of practice and familiarity to spot quickly.
Both cross and outer apply can be used in similar ways to subqueries in the select list, with the added bonus that you can return multiple columns and rows with apply, which you can’t do in a normal subquery.
What Apply Does
The way to think about what apply is doing when a query runs is supplying a table-valued result on the inner side of a join for each row supplied by the outer side of a join.
Here’s a simple example:
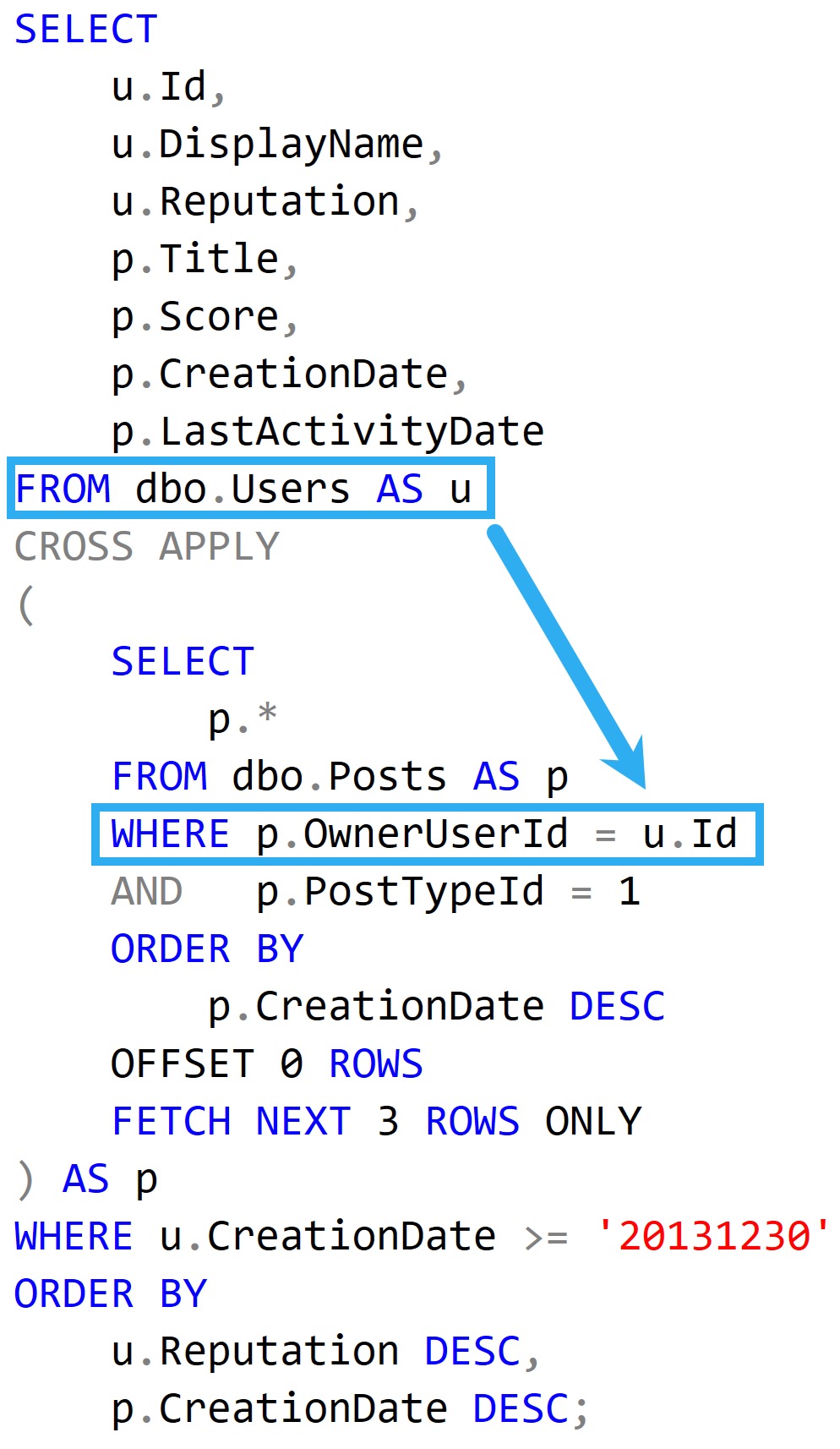
SELECT
u.Id,
u.DisplayName,
u.Reputation,
p.Title,
p.Score,
p.CreationDate,
p.LastActivityDate
FROM dbo.Users AS u
CROSS APPLY
(
SELECT
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.PostTypeId = 1
ORDER BY
p.CreationDate DESC
OFFSET 0 ROWS
FETCH NEXT 3 ROWS ONLY
) AS p
WHERE u.CreationDate >= '20131230'
ORDER BY
u.Reputation DESC,
p.CreationDate DESC;
We’re getting everyone from the Users table who Posted a Question in the final days of 2013, ordered by when it was Created.
For every qualifying User, we get a tabular result showing the Title, Score, CreationDate, and LastActivityDate of their question.
You can picture it sort of like this:
tabular
Some Users have have more than three results, and some may have fewer than three results, but since the query is self-limited to only the first three, our query sets a row goal and quits once three are found.
More About The Query
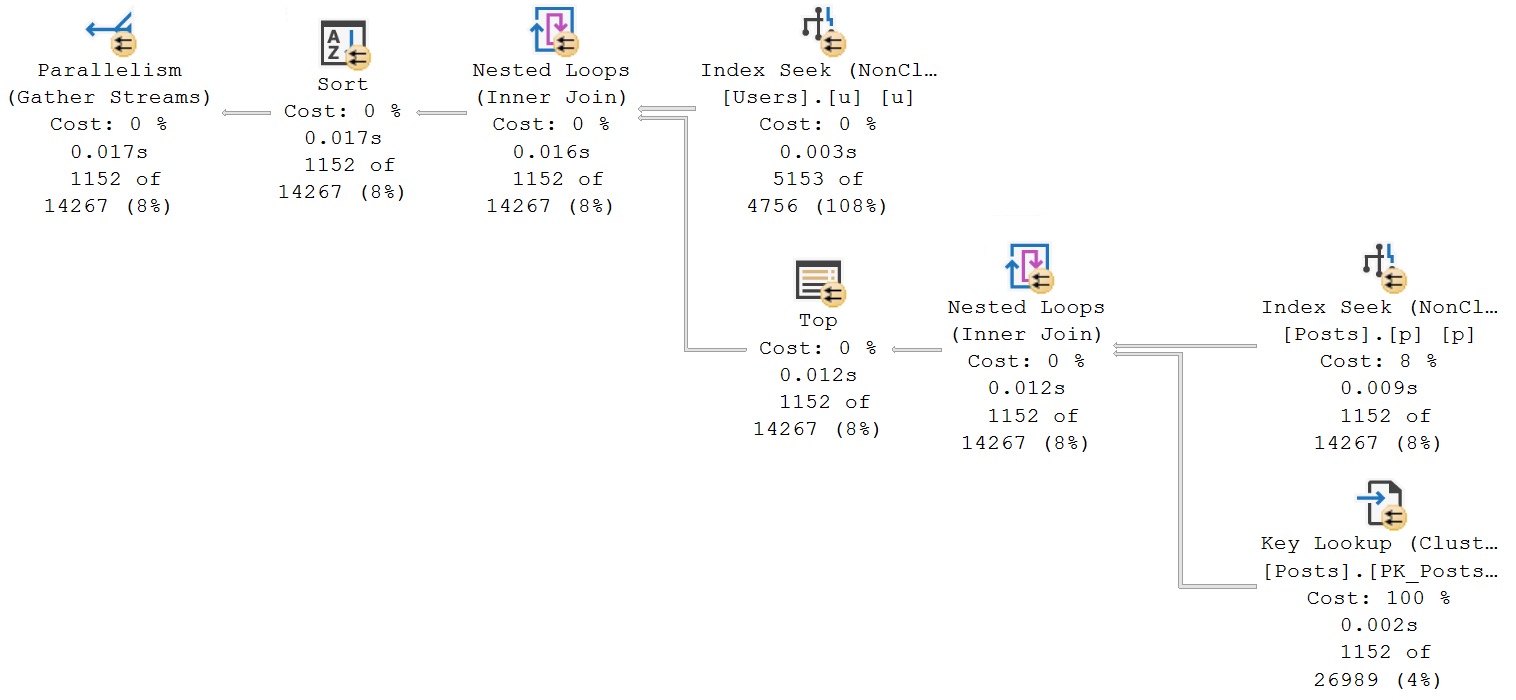
Because the Users table is correlated by Id to the Posts table on OwnerUserId, we need to make sure we have a good index to make that access seekable.
apply-ular
Also because we’re only looking for Questions (PostTypeId = 1), and ordering by the most recent ones (CreationDate DESC), it’s also a wise idea to have those in the key.
It’s also worth talking over an interesting point in the query itself: The select from Posts inside of the apply is doing a select star, sure, but the outer query is only pulling a few of the columns. The optimizer can recognize this, which means we don’t need a gigantic covering index to make this query fast. We also… Don’t really need a covering index at all in this case. Just the key columns are good enough.
CREATE INDEX
u
ON dbo.Users
(CreationDate, Reputation, Id)
INCLUDE
(DisplayName)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
p
ON dbo.Posts
(OwnerUserId, PostTypeId, CreationDate)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Efficiency Unit
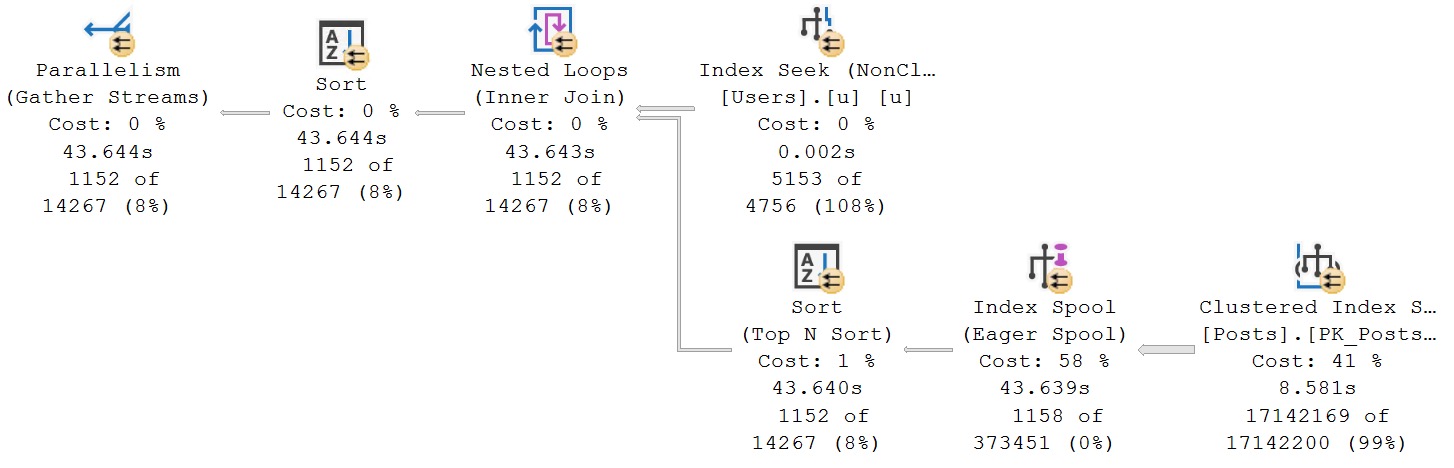
An efficient query plan when using apply will look like this:
hello.
An inefficient query plan using apply will look like this:
oops
If you’re experimenting with apply, either cross or outer, pay close attention to the query plans. If someone says “cross apply is always slow”, you can bet they stink at indexes.
Choices, Choices
The choice to use apply at all depends on the goal of the query, and the goals of the query tuner. It’s not always a magic performance bullet, but under the right circumstances, it can really make things fly.
The choice to use cross or outer apply depends on the semantics of the starting query. An inner join commutes easily to cross apply, and a left join commutes easily to outer apply.
One important difference in how the joins are implemented is in the optimizer’s choice between normal nested loops, where the join is done at the nested loops operator, and apply nested loops, which is when the join keys are pushed to an index seek on the inner side of the join.
The optimizer is capable of transforming an apply to a join and vice versa. It generally tries to rewrite apply to join during initial compilation to maximize the searchable plan space during cost-based optimization. Having transformed an apply to a join early on, it may also consider a transformation back to an apply shape later on to assess the merits of e.g. an index loops join.
Just writing a query using apply doesn’t guarantee that you get the apply nested loops version of a nested loops join. Having solid indexes and easy to search predicates can help push things in the right direction.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I think subqueries in select lists are very neat things. You can use them to skip a lot of additional join logic, which can have all sorts of strange repercussions on query optimization, particularly if you use have to use left joins to avoid eliminating results.
Subqueries do have their limitations:
They can only return one row
They can only return one column
But used in the right way, they can be an excellent method to retrieve results without worrying about what kind of join you’re doing, and how the optimizer might try to rearrange it into the mix.
Since subqueries are in the select list, and can’t eliminate rows from results, you will most commonly see them incorporated late in query plans (much further to the left) as outer joins. The optimizer is generally smart enough to retrieve data for select list subqueries after as much other filtering that can have been applied is applied, so they can be evaluated for as few rows in the outer results as possible.
The most important thing you can do as a developer to make sure your select list subqueries are fast is to make sure you have good supporting indexes for them.
Well Done
Let’s start with this query:
SELECT
u.Id,
u.DisplayName,
u.Reputation,
TopQuestionScore =
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.OwnerUserId = u.Id
ORDER BY
p.Score DESC,
p.Id DESC
),
TopAnswerScore =
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.OwnerUserId = u.Id
ORDER BY
p.Score DESC,
p.Id DESC
),
TotalPosts =
(
SELECT
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.PostTypeId IN (1, 2)
)
FROM dbo.Users AS u
WHERE u.Reputation > 500000
ORDER BY
u.Reputation DESC;
The goal is to find every User with a Reputation over 500,000, and then find their:
Top scoring question (with a unique tie-breaker on most recent post id)
Top scoring answer (with a unique tie-breaker on most recent post id)
Total questions and answers
You might look at this query with a deep sense of impending dread, wondering why we should make three trips to the Posts table to get this information. I totally get that.
But let’s say we have these indexes in place:
CREATE INDEX
u
ON dbo.Users
(Reputation, Id)
INCLUDE
(DisplayName)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
p
ON dbo.Posts
(OwnerUserId, PostTypeId, Score)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
They have everything we need to support quick, navigational lookups.
Query Planner
The query plan for this arrangement looks like this, finishing in 23 milliseconds.
all i need
If you write select list subqueries, and they’re terribly slow, there’s a very good chance that the indexes you have in place are not up to the job, particularly if you see Eager Index Spools in the query plan.
All of the time in the plan is spent in the final subquery, that counts the total number of questions and answers. But even that, at 23 milliseconds, is not worth heaving our chests over.
Three round trips are not at all a problem here, but let’s compare.
One Way Ticket
I’m not opposed to experimentation. After all, it’s a great way to learn, observe, and become enraged with the state of query optimization generally.
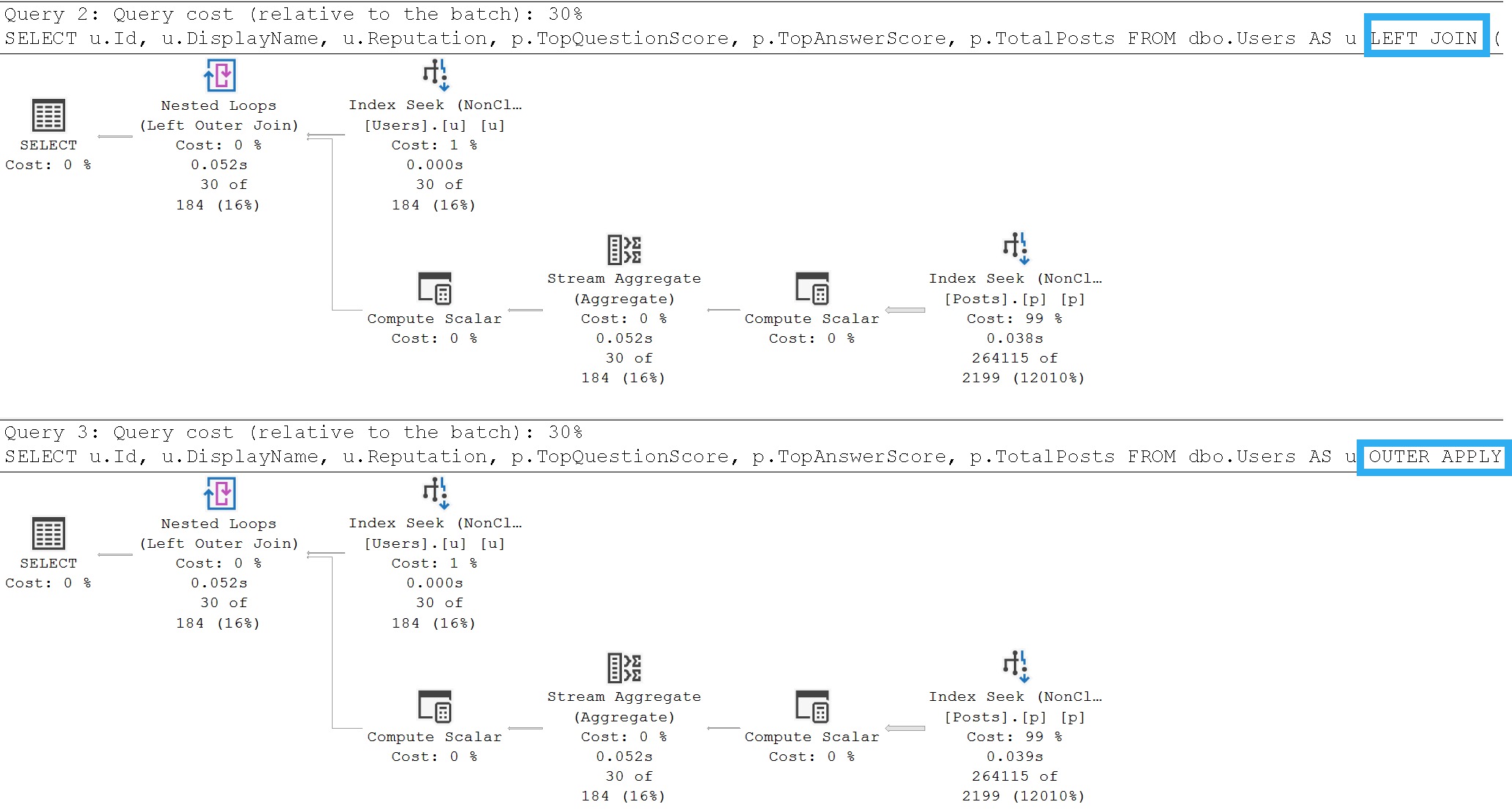
Here are two rewrites of the above query, to only make one trip to the Posts table. The first one uses a derived join, and the second uses apply. They’re both written to use outer joins, to match the semantics of the three subqueries:
/*
Join
*/
SELECT
u.Id,
u.DisplayName,
u.Reputation,
p.TopQuestionScore,
p.TopAnswerScore,
p.TotalPosts
FROM dbo.Users AS u
LEFT JOIN
(
SELECT
p.OwnerUserId,
TopQuestionScore =
MAX(CASE WHEN p.PostTypeId = 1 THEN p.Score ELSE NULL END),
TopAnswerScore =
MAX(CASE WHEN p.PostTypeId = 2 THEN p.Score ELSE NULL END),
TotalPosts =
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
GROUP BY
p.OwnerUserId
) AS p
ON p.OwnerUserId = u.Id
WHERE u.Reputation > 500000
ORDER BY
u.Reputation DESC;
/*
Apply
*/
SELECT
u.Id,
u.DisplayName,
u.Reputation,
p.TopQuestionScore,
p.TopAnswerScore,
p.TotalPosts
FROM dbo.Users AS u
OUTER APPLY
(
SELECT
p.OwnerUserId,
TopQuestionScore =
MAX(CASE WHEN p.PostTypeId = 1 THEN p.Score ELSE NULL END),
TopAnswerScore =
MAX(CASE WHEN p.PostTypeId = 2 THEN p.Score ELSE NULL END),
TotalPosts =
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.PostTypeId IN (1, 2)
GROUP BY
p.OwnerUserId
) AS p
WHERE u.Reputation > 500000
ORDER BY
u.Reputation DESC;
A somewhat brief digression here: Query rewrites to use specific syntax arrangements are often not available in ORMs. Many times while working with clients, we’ll stumble across a bushel of quite painful application-generated queries. I’ll show them useful rewrites to improve things, and we’ll all marvel together at how much better things are. I’ll suggest implementing the rewrite as a stored procedure, and all hell will break loose.
Please don’t be one of those developers. Understand the limitations of the technology stack you’re working with. Not everything produced by code is good.
Compare and Contrast
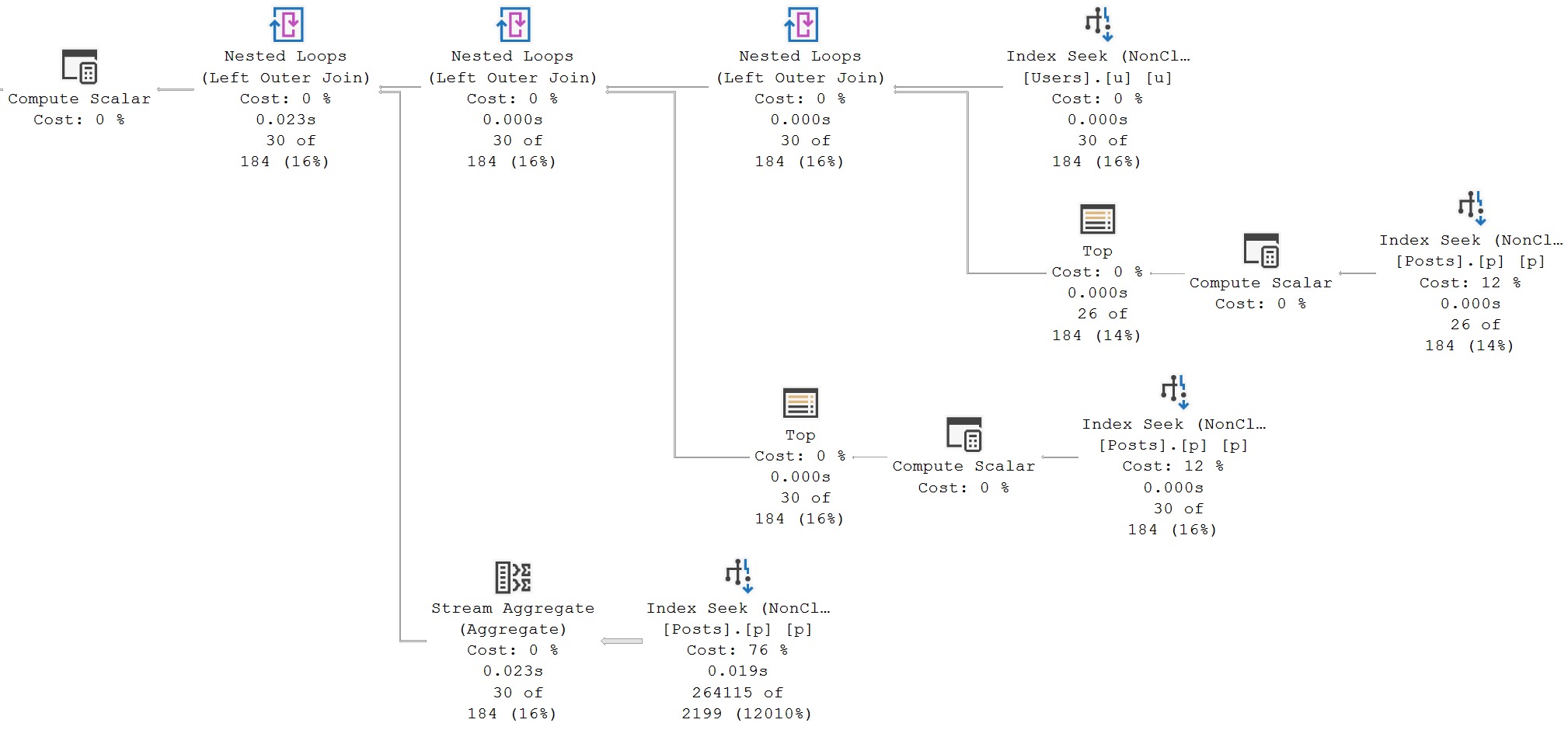
In this case, both of the attempts at rewrites result in identical query plans. The optimizer does a good job here, but both of the single-trip queries is about 2x slower than the original.
In this case, that difference will look and feel microscopic. And it is, mostly because I provided indexes so good that you could write this query any which way and it would work out pretty well.
back of the van
While one round trip certainly felt more efficient than three, each trip from outer to inner side of the nested loops had a bit more work to do each time, and that added up.
It’s nothing consequential here, but you may run into plenty of situations where it’s far worse (or to be fair, far better).
For me, the real advantage of writing out the three separate subqueries is to better understand which one(s) do the most work, and might need additional work done to make them fast.
When you do everything all at once, you have no idea which piece is responsible for slowdowns. We know from the very first query plan that getting the full count does the most work, but that wouldn’t be obvious to me, you, or anyone else looking at the two query plans in this section.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.