Scripts Ahoy
There are a million scripts out there that will give you all of the missing index requests for a database (or even a whole server).
Some will even try to prioritize based on the metrics logged along with each request.
Right now, most of you get:
- Uses: How many times a query compiled that could have used the index
- Average Query Cost: A unit-less cost used by the optimizer for choosing a plan
- Impact: A metric relative to the unit-less cost of the operator the index will help
Breaking each of those down, the only one that has a concrete meaning is Uses, but that of course doesn’t mean that a query took a long time or is even terribly inefficient.
That leaves us with Average Query Cost, which is the sum of each operator’s estimated cost in the query plan, and Impact.
But where does Impact come from?
Impactful
Let’s look at a query plan with a missing index request to figure out what the Impact metric is tied to.
Here’s the relevant part of the plan:
And here’s the missing index request:
/* The Query Processor estimates that implementing the following index could improve the query cost by 16.9141%. */ /* USE [StackOverflow2013] GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Comments] ([Score]) INCLUDE ([PostId]) GO */
Here’s the breakdown:
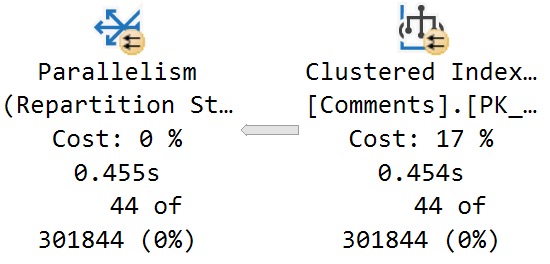
- The optimizer estimates that hitting the Comments table will cost 762 query bucks, which is 17% of the total plan cost
- The optimizer further estimates that hitting the Comments table with the suggested index will reduce the total plan cost by 16.9%
Here’s the relevant properties from the scan of the Comments table:

What I want you to take away from this is that, while hitting the Comments table may be 17% of the plan’s total estimated cost, the time spent scanning that index is not 17% of the plan’s total execution time, either in CPU or duration.
You can see in the screenshot above that it takes around 450ms to perform the full scan of 24,534,730 rows.
Doubtful
In full, this query runs for around 23 seconds:

The estimated cost of hitting the Comments tables is not 17% of the execution time. That time lives elsewhere, which we’ll get to.
In the meantime, there are two more egregious problems to deal with:
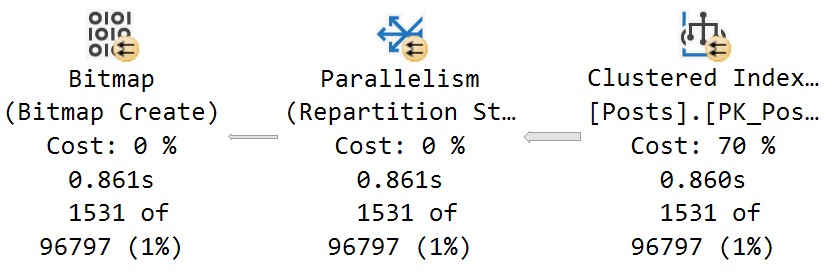
- The optimizer severely miscalculates the cost of scanning the Posts table at 70% (note the 860ms time here):
2. It buries other missing index requests in the properties of the root operator:
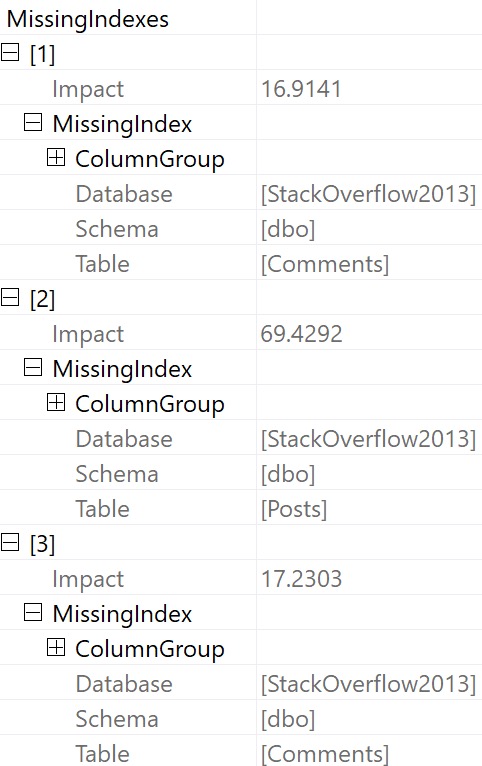
Now, there are two other missing index requests listed here that are a) of higher “impact” b) not ordered by that impact number and c) even if both a and b were true, we know that adding those indexes would not substantially reduce the overall runtime of the stored procedure.
Assuming that we added every single missing index here, at best we would reduce the estimated cost of the plan by 87%, while only reducing the actual execution time of the plan by about 1.3 seconds out of 23 seconds.
Not a big win, here.
Hurtful
Examining where time is spent in this plan, this branch will stick out as the dominating factor:
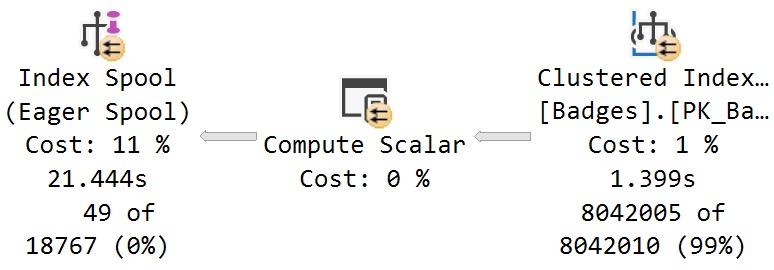
Some interesting things to note here, while we’re talking about interesting things:
- The scan of the Badges table takes 1.4 seconds, and has an estimated cost of 1%
- The estimated cost of the eager index spool is 11%, but accounts for 20 seconds of elapsed time (less the 1.4 seconds for the scan of Badges)
- There was no missing index request generated for the Badges table, despite the optimizer creating one on the fly
This is a bit of the danger in creating missing index requests without first validating which queries generated them, and where the benefit in having them would be.
In tomorrow’s post, we’ll look at how SQL Server 2019 makes figuring this stuff out easier.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “What Do Missing Index Requests Really Mean In SQL Server?”
Comments are closed.