What I Mean Is
You already know that your temp table needs an index. Let’s say there’s some query plan ouchie from not adding one. You’ve already realized that you should probably use a clustered index rather than a nonclustered index. Adding a nonclustered index leaves you with a heap and an index, and there are a lot of times when nonclustered indexes won’t be used because they don’t cover the query columns enough.
Good. We’ve fixed you.
But, like, when should you create the index?
Options
You can do one of these things:
- Inline, when you create the table
- After you create the table
- After you load data into the table
This requires a bit of testing to get right.
Inline
In many cases, this is the best option, for reasons outlined by Pam Lahoud.
Do not explicitly drop temp tables at the end of a stored procedure, they will get cleaned up when the session that created them ends.
Do not alter temp tables after they have been created.
Do not truncate temp tables
Move index creation statements on temp tables to the new inline index creation syntax that was introduced in SQL Server 2014.
Where it can be a bad option is:
- If you can’t get a parallel insert even with a TABLOCK hint
- Sorting the data to match index order on insert could result in some discomfort
After Creation
This is almost always not ideal, unless you want to avoid caching the temp table, and for the recompilation to occur for whatever reason.
It’s not that I’d ever rule this out as an option, but I’d wanna have a good reason for it.
Probably even several.
After Insert
This can sometimes be a good option if the query plan you get from inserting into the index is deficient in some way.
Like I mentioned up above, maybe you lose parallel insert, or maybe the DML Request Sort is a thorn in your side.
This can be awesome! Except on Standard Edition, where you can’t create indexes in parallel. Which picks off one of the reasons for doing this in the first place, and also potentially causes you headaches with not caching temp tables, and statement level recompiles.
One upside here is that if you insert data into a temp table with an index, and then run a query that causes statistics generation, you’ll almost certainly get the default sampling rate. That could potentially cause other annoyances. Creating the index after loading data means you get the full scan stats.
Hooray, I guess.
This may not ever be the end of the world, but here’s a quick example:
DROP TABLE IF EXISTS #t;
GO
--Create a table with an index already on it
CREATE TABLE #t(id INT, INDEX c CLUSTERED(id));
--Load data
INSERT #t WITH(TABLOCK)
SELECT p.OwnerUserId
FROM dbo.Posts AS p;
--Run a query to generate statistics
SELECT COUNT(*)
FROM #t AS t
WHERE t.id BETWEEN 1 AND 10000
GO
--See what's poppin'
SELECT hist.step_number, hist.range_high_key, hist.range_rows,
hist.equal_rows, hist.distinct_range_rows, hist.average_range_rows
FROM tempdb.sys.stats AS s
CROSS APPLY tempdb.sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS hist
WHERE OBJECT_NAME(s.object_id, 2) LIKE '#t%'
GO
DROP TABLE #t;
--Create a query with no index
CREATE TABLE #t(id INT NOT NULL);
--Load data
INSERT #t WITH(TABLOCK)
SELECT p.OwnerUserId
FROM dbo.Posts AS p;
--Create the index
CREATE CLUSTERED INDEX c ON #t(id);
--Run a query to generate statistics
SELECT COUNT(*)
FROM #t AS t
WHERE t.id BETWEEN 1 AND 10000
--See what's poppin'
SELECT hist.step_number, hist.range_high_key, hist.range_rows,
hist.equal_rows, hist.distinct_range_rows, hist.average_range_rows
FROM tempdb.sys.stats AS s
CROSS APPLY tempdb.sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS hist
WHERE OBJECT_NAME(s.object_id, 2) LIKE '#t%'
GO
DROP TABLE #t;
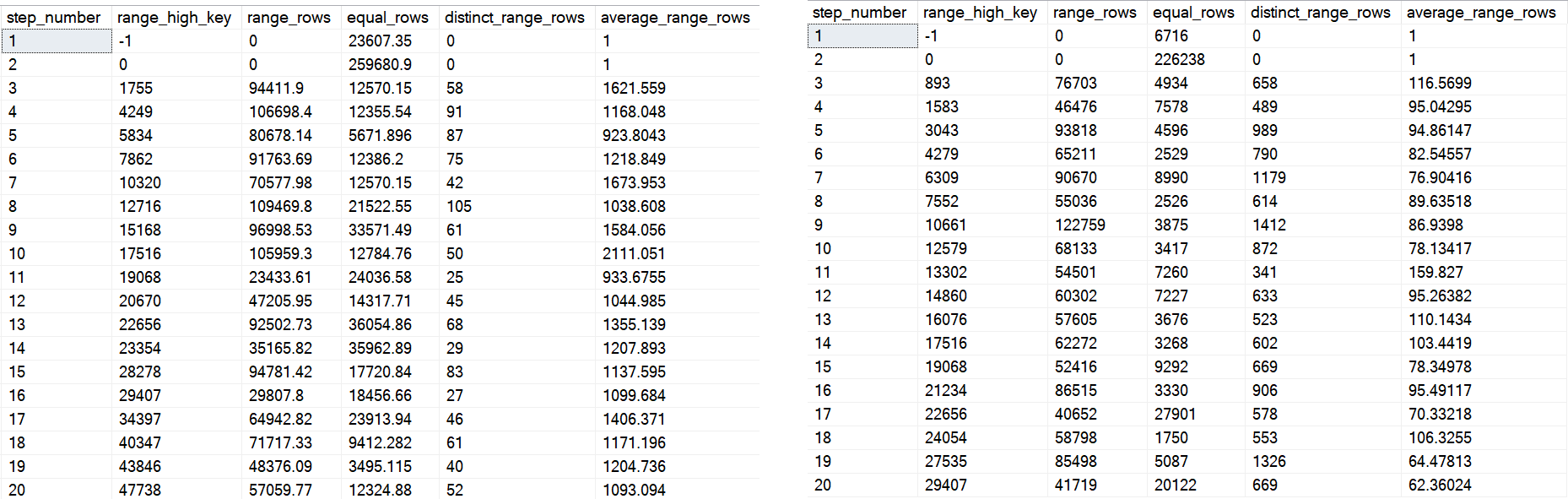
On the left is the first 20 steps from the first histogram, and on the right is the first 20 from the second one.
You can see some big differences — whether or not they end up helping or hurting performance would take a lot of different tests. Quite frankly, it’s probably not where I’d start a performance investigation, but I’d be lying if I told you it never ended up there.
All Things Considerateded
In general, I’d stick to using the inline index creation syntax. If I had to work around issues with that, I’d create the index after loading data, but being on Standard Edition brings some additional considerations around parallel index creation.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
For SQL Server versions 2016 and 2017 it is said that inserts into local temporary tables does not require WITH (TABLOCK) clause.
“INSERT parallelism for INSERTSELECT operations was introduced in SQL Server 2016 or SQL Server 2017 on Windows. INSERTs into local temporary tables (only those identified by the # prefix, and not global temporary tables identified by ## prefixes) are now automatically enabled for parallelism without having to designate the TABLOCK hint that non-temporary tables require. ”
Link: https://support.microsoft.com/en-us/topic/poor-performance-when-you-run-insert-select-operations-in-sql-server-2016-or-sql-server-2017-on-windows-36199169-602f-9da7-9602-dfabba07fb52
SELECT INTOdoesn’t require any hints.INSERT SELECTrequires a TABLOCK hint, and has several limitations.