Easy Rider
When you’re trying to figure out how to store string data, it often seems easiest to just choose an extra long — even MAX — data type to avoid future truncation errors.
Even if you’re storing strings with a known, absolute length, developers may choose to not enforce that in the application, either via a drop down menu or other form of validation.
And so to avoid errors when users try to put their oh-so-important data in their oh-so-expensive database, we get columns added to tables that can fit a galaxy of data in them, when we only need to store an ashtray worth of data.
While getting data into those columns is relatively easy — most application inserts are single rows — getting data out of those columns can be quite painful, whether it’s searching or just presenting in the select portion of a query.
Let’s look at a couple simple examples of how that happens.
Search Engine
Let’s take a query like this one:
SELECT TOP (20)
p.Id,
p.Title,
p.Body
FROM dbo.Posts AS p
WHERE p.Body LIKE N'SQL Server%';
The Body column in the Posts table is nvarchar and MAX, but the same thing would happen with a varchar column.
If you need a simple way to remember how to pronounce those data types, just remember to Pahk yah (n)vahcah in Hahvahd Yahd.
Moving on – while much has been written about leading wildcard searches (that start with a % sign), we don’t do that here. Also, in general, using charindex or patindex instead of leading wildcard like searching won’t buy you all that much (if anything at all).
Anyway, since you can’t put a MAX datatype in the key of an index, part of the problem with them is that there’s no way to efficiently organize the data for searching. Included columns don’t do that, and so we end up with a query plan that looks some-such like this:
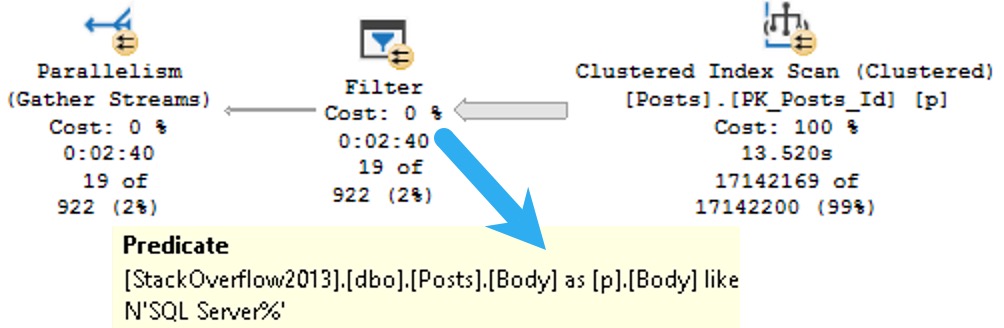
We spend ~13.5 seconds scanning the clustered index on the Posts table, then about two minutes and twenty seven seconds (minus the original 13.5) applying the predicate looking for posts that start with SQL Server.
That’s a pretty long time to track down and return 19 rows.
Let’s change the query a little bit and look at how else big string columns can cause problems.
Memory Bank
Rather than search on the Body column, let’s select some values from it ordered by the Score column.
Since Score isn’t indexed, it’s not sorted in the database. That means SQL Server needs to ask for memory to put the data we’re selecting in the order we’re asking for.
SELECT TOP (200)
p.Body
FROM dbo.Posts AS p
ORDER BY p.Score DESC;
The plan for this query asks for a 5GB memory grant:
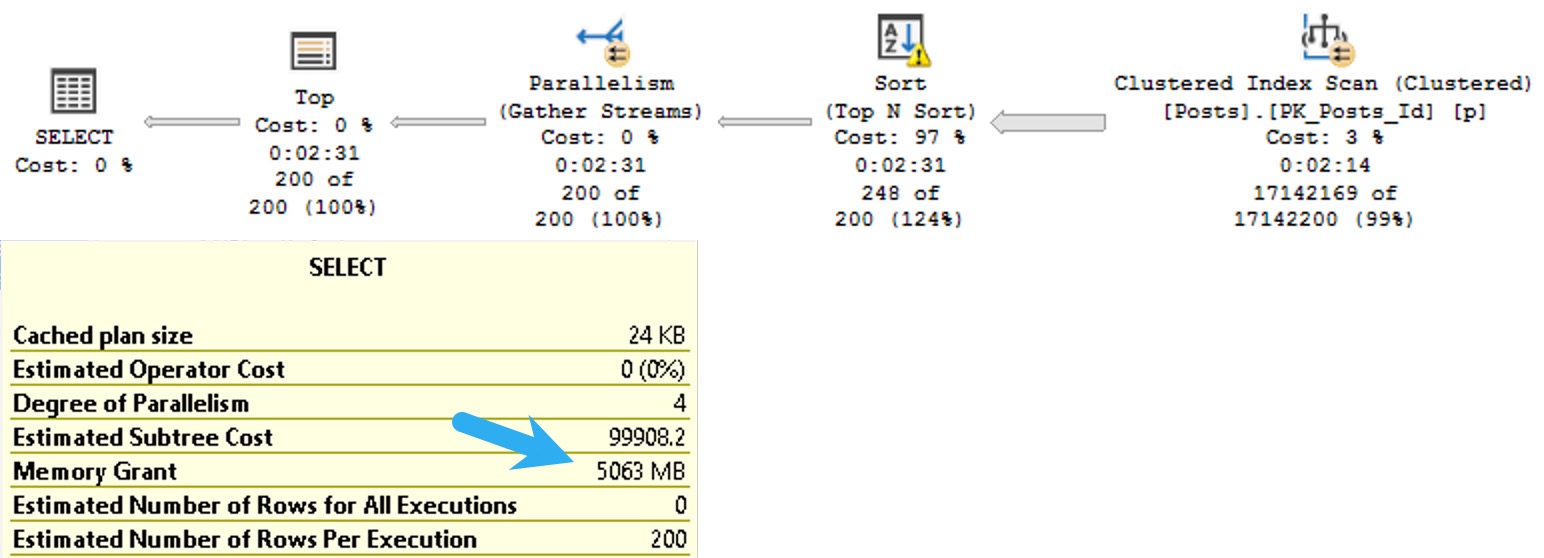
I know what you’re thinking: the Body column probably has some pretty big data in it, and you’re right. In this case, it’s the right data type to use.
The bad news is that SQL Server will makes the same memory grant estimation based on the size of the data we need to sort whether or not it’s a good choice.
I talk more about that in this Q&A on Stack Exchange.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I have noticed that if one uses varchar(max) as parameter for parametrized query, you get a huge execution plan size, even if that parameter contains only like 20 characters
Yep, max parameters have the same problems — they can’t be pushed down to when you touch tables or indexes — just like when a column has a max data type.
Pahk yah (n)vahcah in Hahvahd Yahd? WT.. hahaha!
😃